ModelPack Overview
ModelPack is an advanced computer vision solution developed by Au-Zone Technologies as part of their EdgeFirst.AI middleware. It provides both object detection and semantic segmentation capabilities, enabling high-performance, low-latency AI inference on embedded devices, particularly those with AI accelerators (NPUs) in the 0.5 TOPS and up range.
| Detection | Segmentation | Multitask |
|---|---|---|
 |
 |
 |
ModelPack is optimized for real-time vision applications such as industrial automation, robotics, and autonomous systems. It combines object detection — locating multiple objects within an image using bounding boxes — with instance segmentation, which outlines each object’s exact shape at the pixel level. This unified approach enables detailed scene understanding at the edge and can contribute in a late fusion with the radar model.
Getting Started
ModelPack can be trained now in EdgeFirst Studio using a Graphical User Interface by following four simple steps:
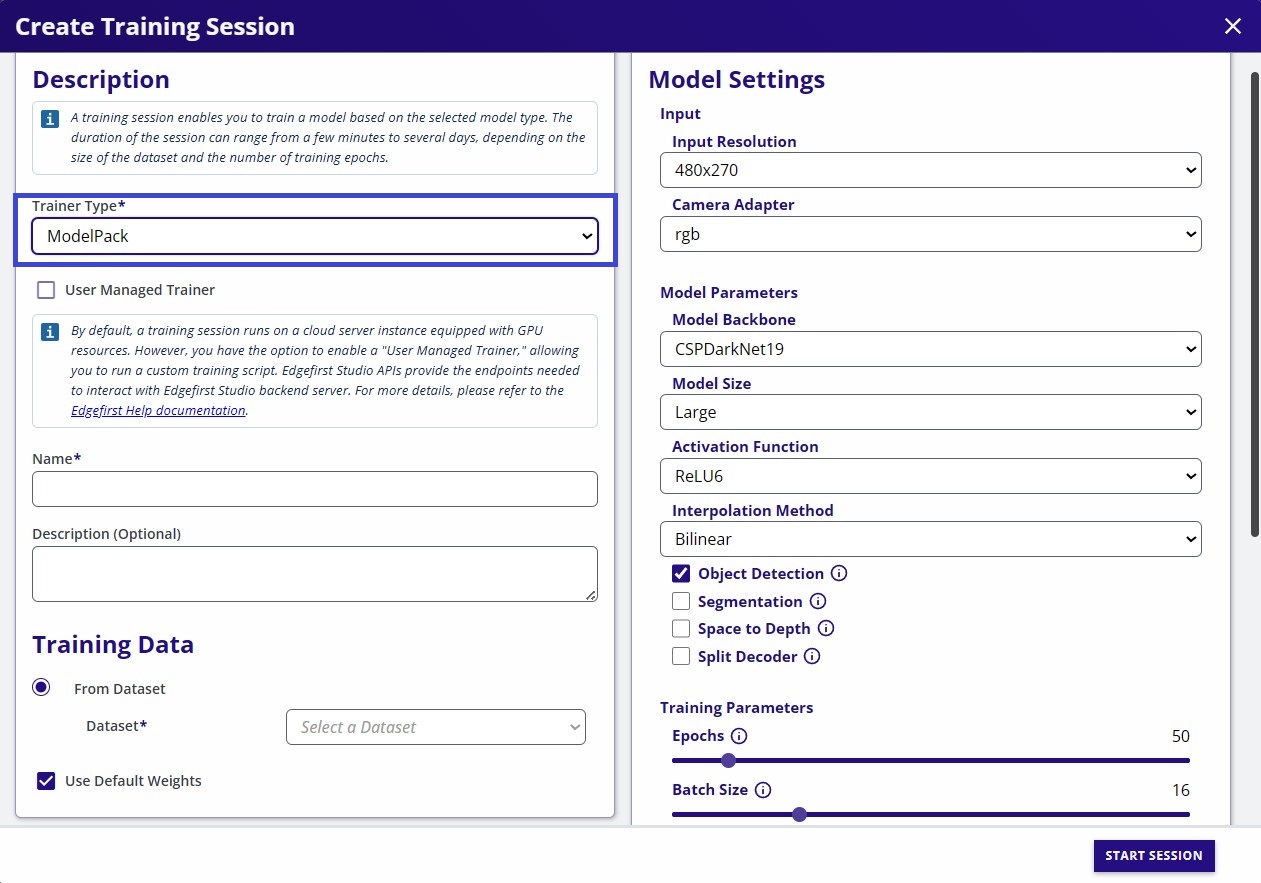
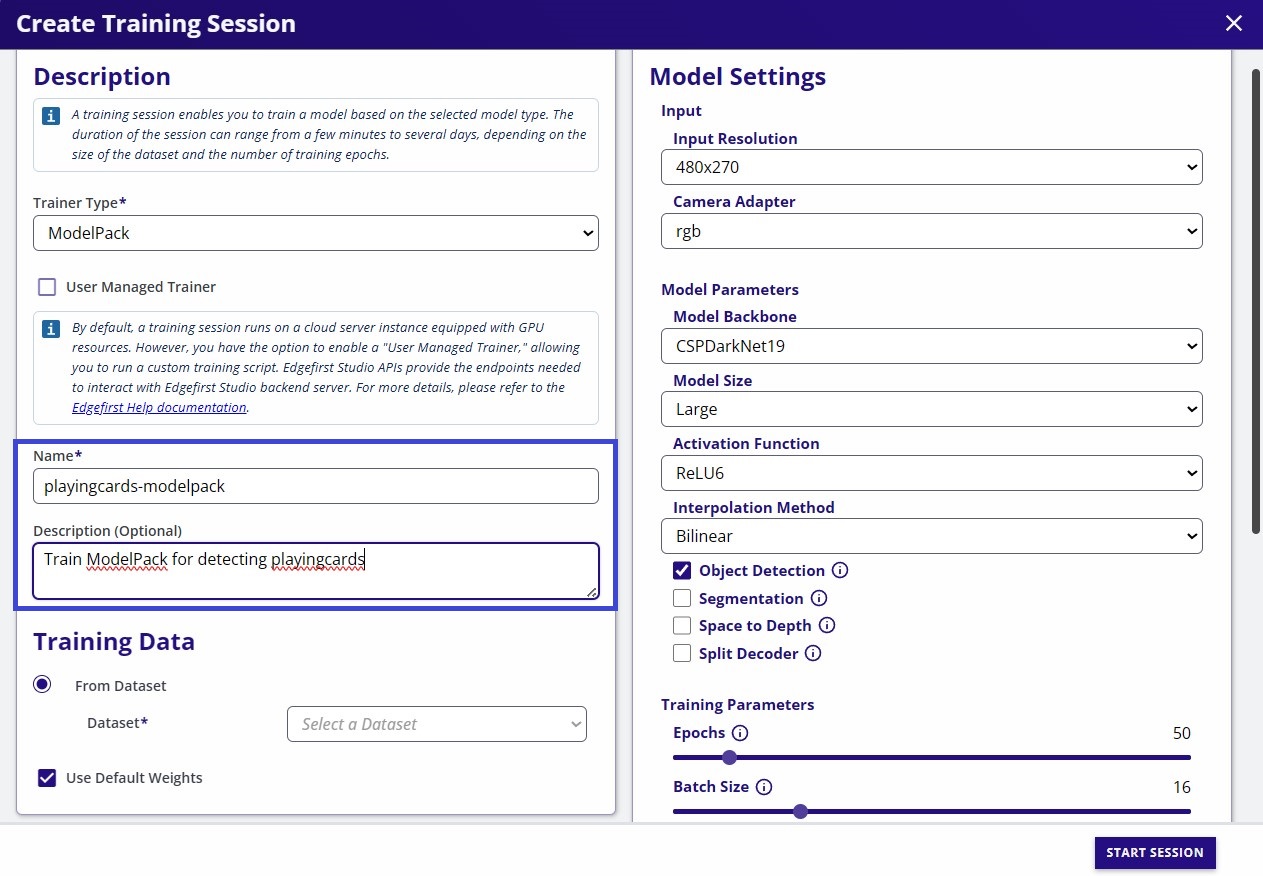
- Set a name and description (optional) for the training session.
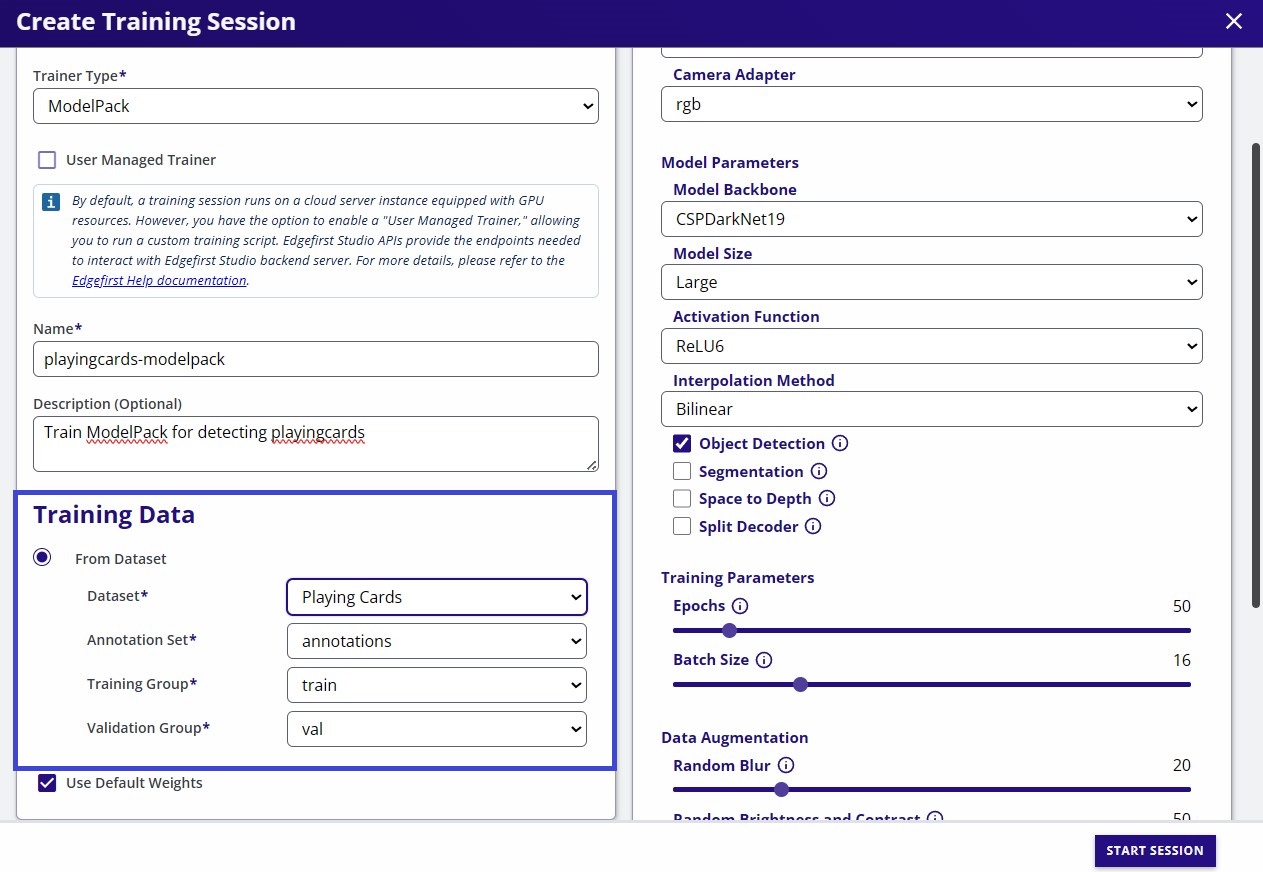
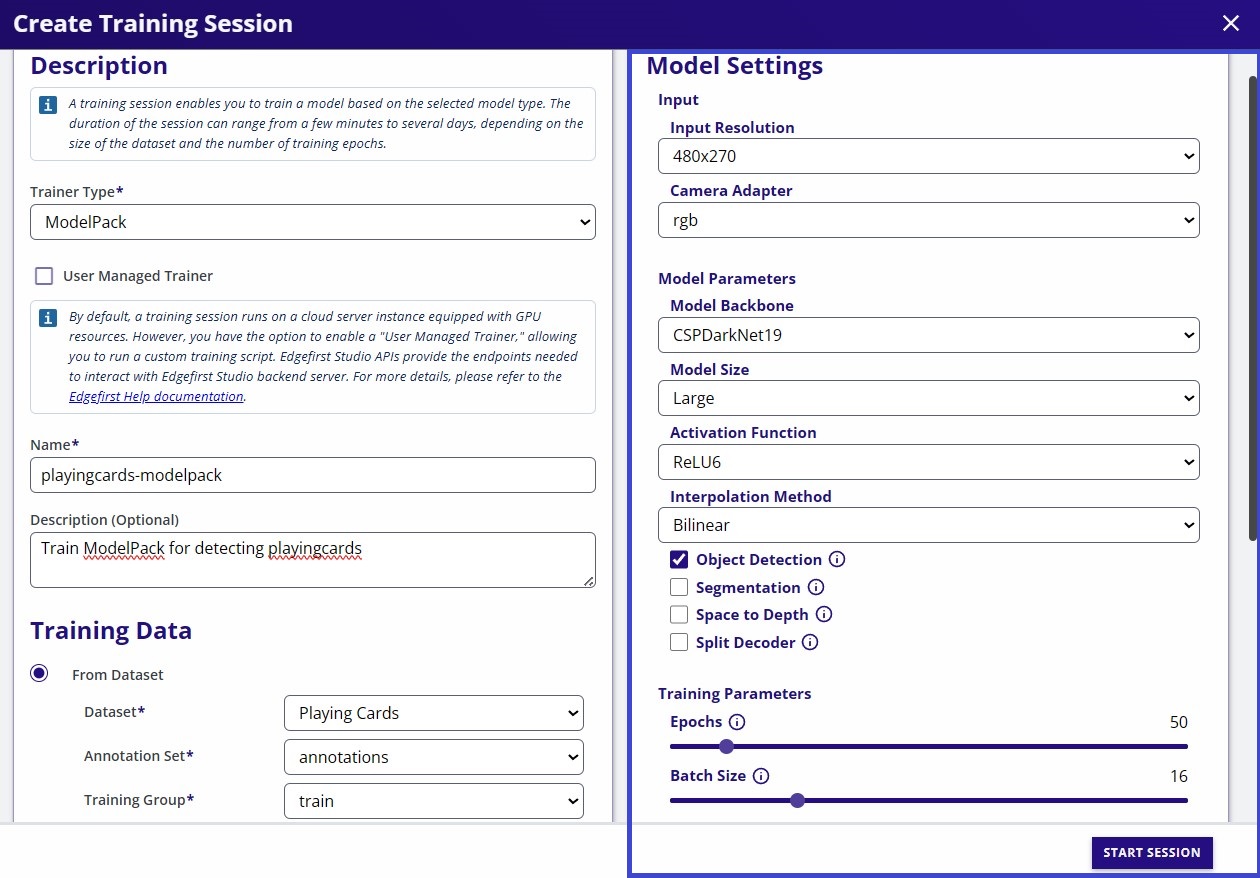
- Configure model parameters (architecture, input size, epochs, etc.) and start Training.
- Model Name: This field specifies the name of the training session and will be used to name the artifacts (e.g.
modelpack-coffecup-640x640-rgba-t-<session ID>.tfliteormodelpack-coffecup-640x640-rgba-t-<session ID>.onnx) - Description: This field is used to add some hints about the training session. Commonly used to highlight some parameters
- Training Data: In this section the user must select the dataset as well as train/val groups
- Input Resolution: The user can pick predefined input resolutions. Even when ModelPack accepts any resolution we keep this option as simple as possible. In case you need a different resolution to be supported, please reach out and email our support team
- Camera Adaptor: ModelPack accepts six different input optimizations. It could be either of RGB, BGR, RGBA, BGRA, Greyscale, or YUYV
- Model Parameters: This section configures the model architecture
- Model Backbone: Model backbone exposes a CSPDarknet19 optimized for boosting inference time and a CSPDarknet53 optimized for accuracy
- Model Size: Similar to modern architectures, ModelPack also accepts dynamic scaling factors (
width in [0.25, 0.5, 0.75, 1.0],depth in [0.33, 0.33, 0.66, 1.0]) - Activation Function: This parameter defines the main activation used in the model. Exposed values are ReLU, ReLU6 and SiLU. The best tradeoff between speed and accuracy is produced by ReLU6 activation in most of the cases
- Interpolation Method: Model upsample layers are ruled by a resize operation. This operation can run with two different algorithms:
BilinearorNearest - Object Detection: Enables object detection task (enabled by default)
- Segmentation: Enables Semantic Segmentation
- Space to Depth: This feature enables the Space to Depth Transformation to the input in order to reduce model complexity on higher resolutions
- Split Decoder: Remove the decoder from the model and use a very optimized one from EdgeFirst. This feature is very useful when the location of the boxes has to be precise (0-offset)
-
Training Parameters: In this section the user is able to specify the number of epochs to train the model as well as the batch size. Remember the larger the input resolution the smaller the batch size
-
Use Default Weights: When enabled (default), training starts from pre-trained COCO weights. When disabled, starting weights are sourced from a prior training session you specify.
ModelPack does not have an Enable Training checkbox
For ModelPack training always runs. Disabling Use Default Weights lets you supply a prior session's weights as the starting point; leaving it enabled trains from COCO pre-trained weights. Enable Training are Ultralytics-only and do not apply here
-
-
Data Augmentation: This section controls the probability of each augmentation technique. This feature is crucial for training models and reduce overfitting, especially in small datasets
- Export Parameters: Allow the user to set a portion of data for calibration when exporting the model for INT8 quantization
- Start Session: This button will start the training session
ModelPack Architecture
ModelPack is a modern object detector and it adopts similar scaling strategies seen in the YOLO family models. The model expands and contracts based on the width and height parameters. ModelPack shares two main backbones: a Darknet53 backbone similar to YOLOx which maximizes accuracy and a Darknet19 backbone for boosting inference time. Different than YOLOx, ModelPack is NOT anchor free, which makes the model more accurate and stable after quantization.
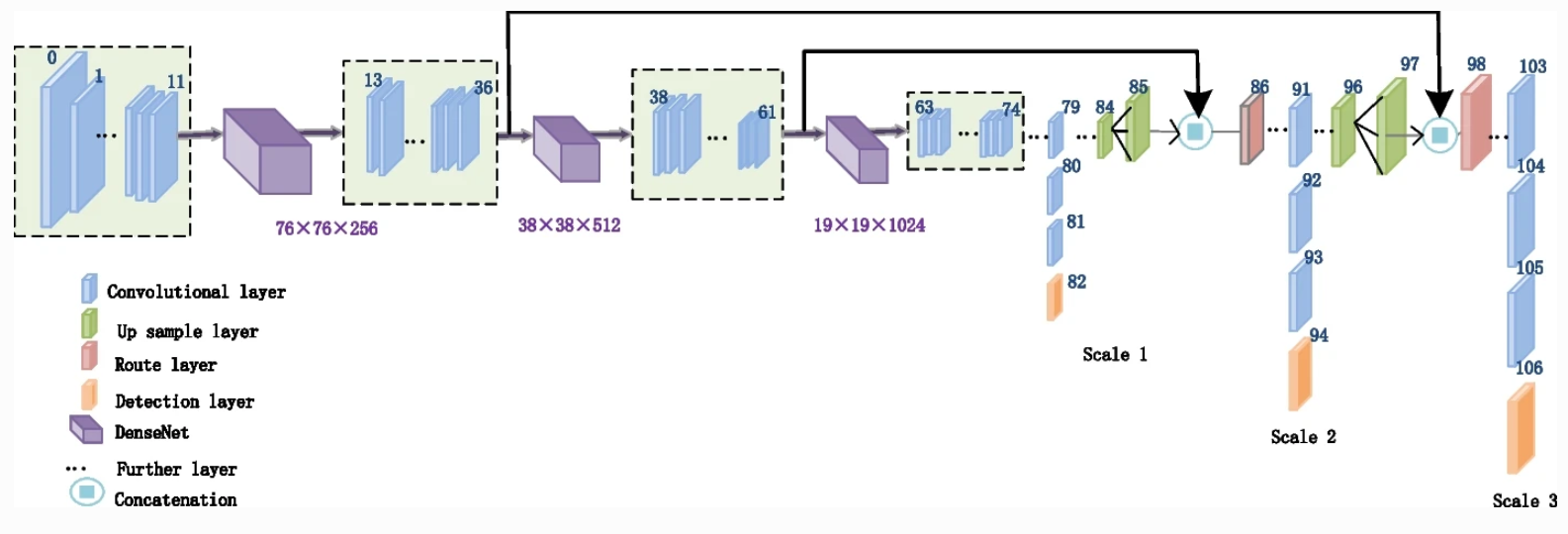
Figure reproduced from: Yang, L., Chen, G. & Ci, W. Multiclass objects detection
As mentioned above, ModelPack merges Semantic Segmentation and Object Detection on the same model and it is user responsibility depending on problem requirements. Semantic Segmentation only uses two scales (Scale 1 and Scale 2). On the other hand, Object Detection task uses the three scales.
While solving both tasks in the same inference cycle, the three scales are used.
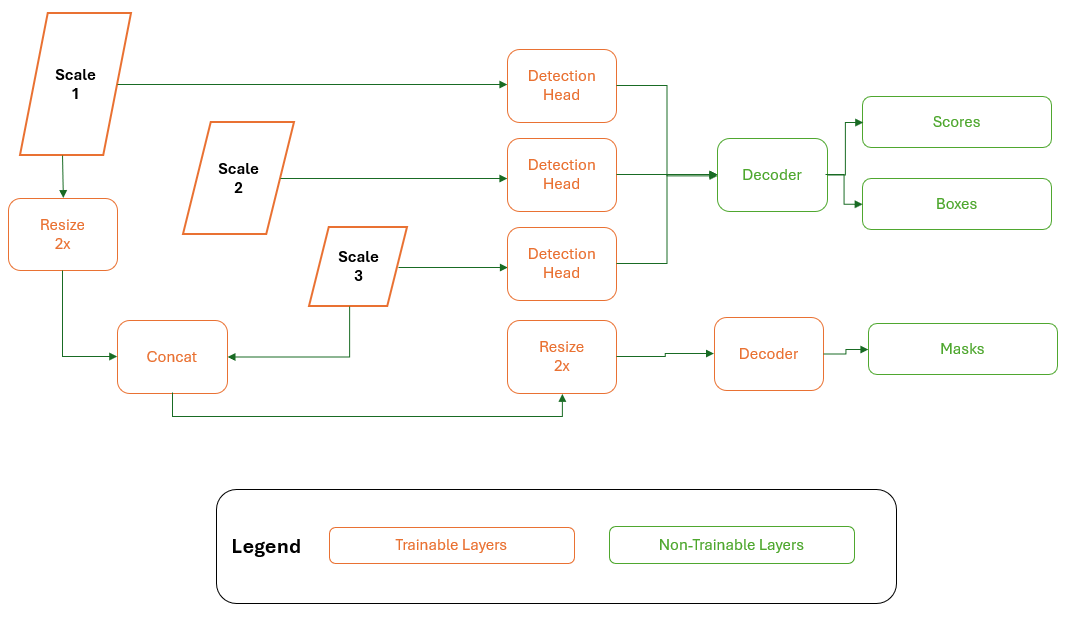
ModelPack outputs can be configured on Studio User Interface as explained in the ModelPack training guide.