Neutron Converter
The Neutron Converter re-encodes a quantized TFLite model for execution on NXP eIQ Neutron NPUs. It is the conversion step for the i.MX 95, the wider i.MX 94x application-processor family, the S32N79 automotive MPU, and the Neutron-C microcontroller class (MCX N54x / N94x, i.MX RT700, S32K5).
Neutron Converter is a re-encoder, not a quantizer — all quantization decisions are made upstream by the TFLite Converter. If the matching quantized TFLite artifact does not already exist when the Neutron Converter launches, Studio triggers the TFLite Converter automatically and waits for it to complete. From the user's perspective the conversion is a single click; behind the scenes it is a two-stage pipeline that produces both a deployable TFLite artifact and a Neutron-compiled artifact for the chosen target.
Model Zoo — Supported Models & Benchmarks
For the latest supported model list, per-model validation results, and benchmark numbers across the eIQ Neutron silicon family (i.MX 95, i.MX 94x, and more), see the EdgeFirst Model Zoo on Hugging Face.
Studio Launch Form
The launch form has two field groups: an upstream group plumbed through to the TFLite Converter, and a conversion group that controls the Neutron stage itself.
Upstream TFLite settings
| Field | Values | Default | Meaning |
|---|---|---|---|
upstream.input_dtype |
uint8 / int8 |
uint8 |
Input precision of the upstream TFLite artifact. |
upstream.output_dtype |
int8 / uint8 |
int8 |
Output precision of the upstream TFLite artifact. |
upstream.split_mode |
smart / logical / combined |
smart |
Output-decomposition strategy. See TFLite Converter — split_mode explained. The Neutron stage itself does not change output structure; whatever the upstream TFLite stage produces flows through verbatim. |
Neutron settings
| Field | Values | Default | Meaning |
|---|---|---|---|
target |
imx95 / imx943 / imx952 / s32n79 / mcxn54x / mcxn94x / imxrt700 / s32k5 |
imx95 |
Target Neutron silicon. |
optimization_level |
OFast / OOpt |
OFast |
OFast uses a heuristic scheduler (fast). OOpt uses an exact constraint solver (slower, marginally better schedule; on very large models the solver may time out and the conversion fails — re-run with OFast if that happens). |
force_determinism |
false / true |
false |
Disables multi-threading inside the NXP binary so the compiled output is byte-identical across runs. Useful for CI reproducibility; significantly slower compile time. |
enable_profiling |
false / true |
false |
Emits a per-operation NPU timing table alongside the compiled model. Adds ~5% inference overhead at runtime. |
Target Silicon
The target field selects from two NPU families packaged inside the same product line:
Neutron-S — application-processor class. Larger models, tunneling for layer fusion, support for the full Neutron IR.
| Target | Hardware |
|---|---|
imx95 |
NXP i.MX 95 application processor |
imx943 |
NXP i.MX 943 application processor |
imx952 |
NXP i.MX 952 application processor |
s32n79 |
NXP S32N79 automotive MPU |
Neutron-C — microcontroller class. Memory-constrained, sequencer mode, weight fetching from external memory.
| Target | Hardware |
|---|---|
mcxn54x |
NXP MCX N54x microcontrollers |
mcxn94x |
NXP MCX N94x microcontrollers |
imxrt700 |
NXP i.MX RT700 crossover MCU |
s32k5 |
NXP S32K5 automotive MCU |
Users do not need to know which family their part belongs to — the Neutron Converter passes the target name straight through to the NXP toolchain.
What You Get
A self-contained .tflite flatbuffer with:
- The original TFLite operator graph re-encoded as Neutron microcode for the target.
- The upstream stage's EdgeFirst metadata (
edgefirst.json+labels.txt) preserved verbatim, with a newneutrontraceability block added recording the target, optimization level, and converter version. - The upstream stage's compiled
outputs[]array — the Neutron stage does not modify output structure, so the samesplit_modethat controlled the upstream TFLite quantization also governs the runtime decoder layout.
Deploy through the NXP eIQ Neutron delegate or via the EdgeFirst Perception runtime; the delegate transparently dispatches Neutron-compiled operators to the NPU.
Smart Quantization on Neutron
The Neutron NPU supports most standard TFLite operators, but the decode operations in a detection head (the probability-distribution math, per-class activation) are not in the supported set — on a combined-mode TFLite they fall back to the CPU under the TFLite delegate regardless of whether smart quantization was applied. The benefit of Smart Quantization on Neutron is therefore different from the other targets:
- Faster CPU decode. The runtime's per-scale decoder kernels are NEON-vectorized and hand-tuned for aarch64 — materially faster than the generic float fallback the TFLite delegate would run for the same operations.
- Pipelining. Separating the decoder from the NPU compile boundary lets the runtime overlap NPU inference, CPU decode, and pre/post-processing across threads. The NPU stalls while the CPU runs the decoder (and vice versa) are avoided.
The first effect shows up in single-frame latency; the second shows up in steady-state throughput. Both are reasons to keep upstream.split_mode: smart (the default) even on a Neutron target where the NPU's INT8 operator coverage would let combined execute "on-NPU" in principle.
Converting Your Model
Once training completes in EdgeFirst Studio:
-
Click on the completed training session.
Completed Training Session -
Navigate to the Artifacts tab and click the NXP eIQ Neutron Converter button under Converters on the right.
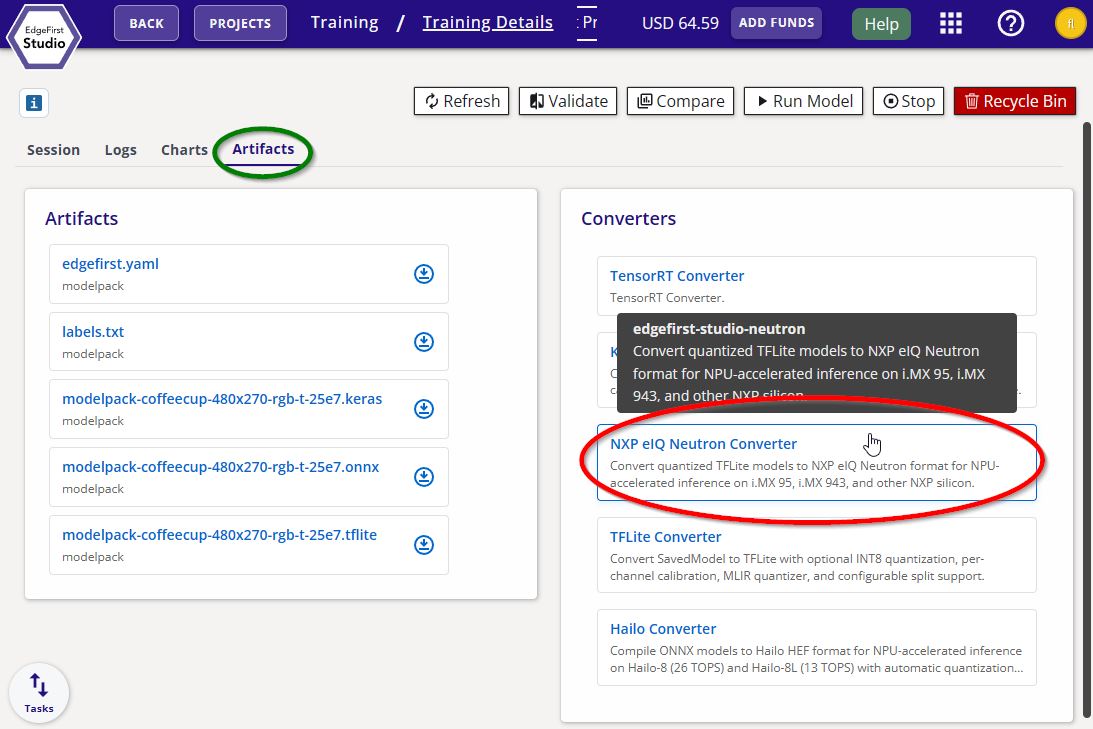
Neutron Converter -
Adjust the I/O precision, split mode, target device, and any other conversion settings as needed, or leave the defaults for best performance. Click Start App to begin the conversion.
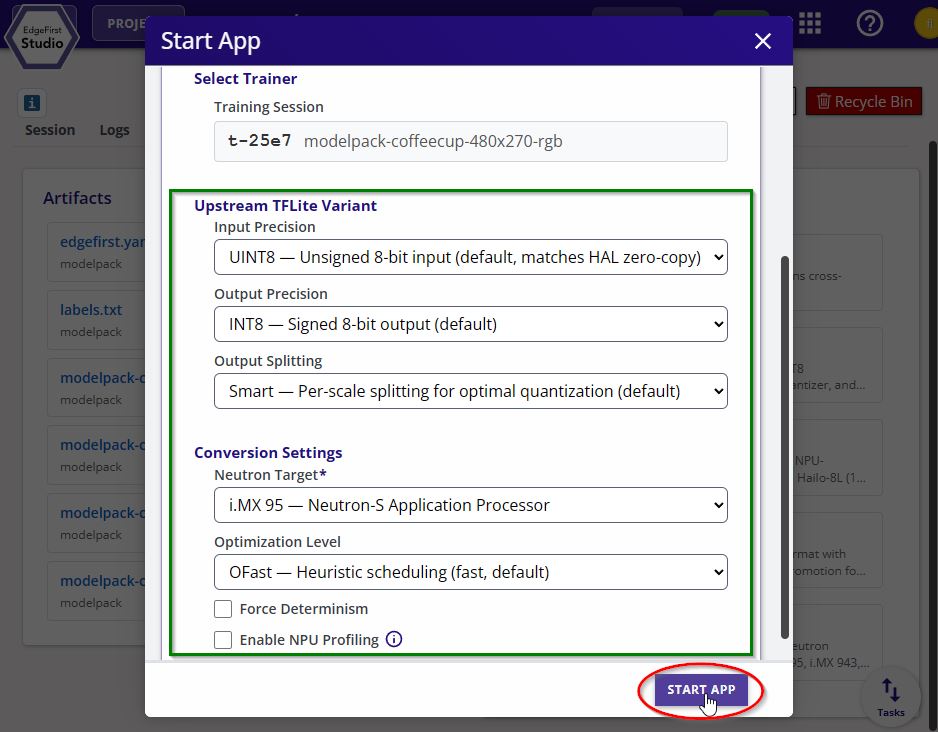
Neutron Converter Options
If the matching upstream TFLite artifact has not been built yet, the Neutron job will trigger the TFLite Converter for you and wait for it to complete before running the Neutron stage — expect the conversion to take noticeably longer in that case.
Known Limitations
- The Neutron stage is INT8-only. The upstream TFLite must be a quantized INT8 artifact; float16 / float32 TFLite is not supported as a Neutron input.
force_determinismsignificantly slows compile time. Enable only when byte-identical reproducibility is required (CI, regression testing).- The Neutron-C targets (
mcxn54x,mcxn94x,imxrt700,s32k5) have stricter SRAM budgets than the Neutron-S targets. Large models may be rejected at compile time with an informative error from the NXP toolchain.