Pipelining
The EdgeFirst Profiler runs a multi-stage measurement pipeline on every frame: image capture, preprocess, inference, postprocess, and output encoding. Each stage exercises a different part of the system — CPU, host memory, bus transfers, NPU/GPU — and on a typical edge target the stages take substantially different amounts of time. Pipelining is the profiler's mechanism for overlapping those stages across frames so the slowest stage sets throughput, instead of the sum of all stage times setting it.
This page explains the conceptual model, the --inference-depth flag that controls it, the per-stage depth flags introduced in 1.5.0, and how each supported backend constrains it.
Pipeline stages
Every frame travels through the same sequence of stages, in order:
| Stage | Hardware | What it does |
|---|---|---|
| capture | CPU (libjpeg / hardware codec) | Read the encoded image file, decode to pixels |
| preprocess | CPU + DMA | Resize, color-convert, quantize into the input tensor |
| inference | NPU / GPU / CPU | Run the model |
| postprocess | CPU | Score-threshold, box decode, NMS, mask decode |
| output | CPU + disk | Write predictions to the in-memory Parquet buffer; periodically flush |
The pycocotools-style accuracy metrics are computed off-device in EdgeFirst Studio after the run completes — they are not part of the on-device pipeline.
Sequential execution (--inference-depth 1)
With --inference-depth 1 the profiler runs each stage on the current frame before starting any stage on the next frame. Each piece of hardware sits idle while the others work:
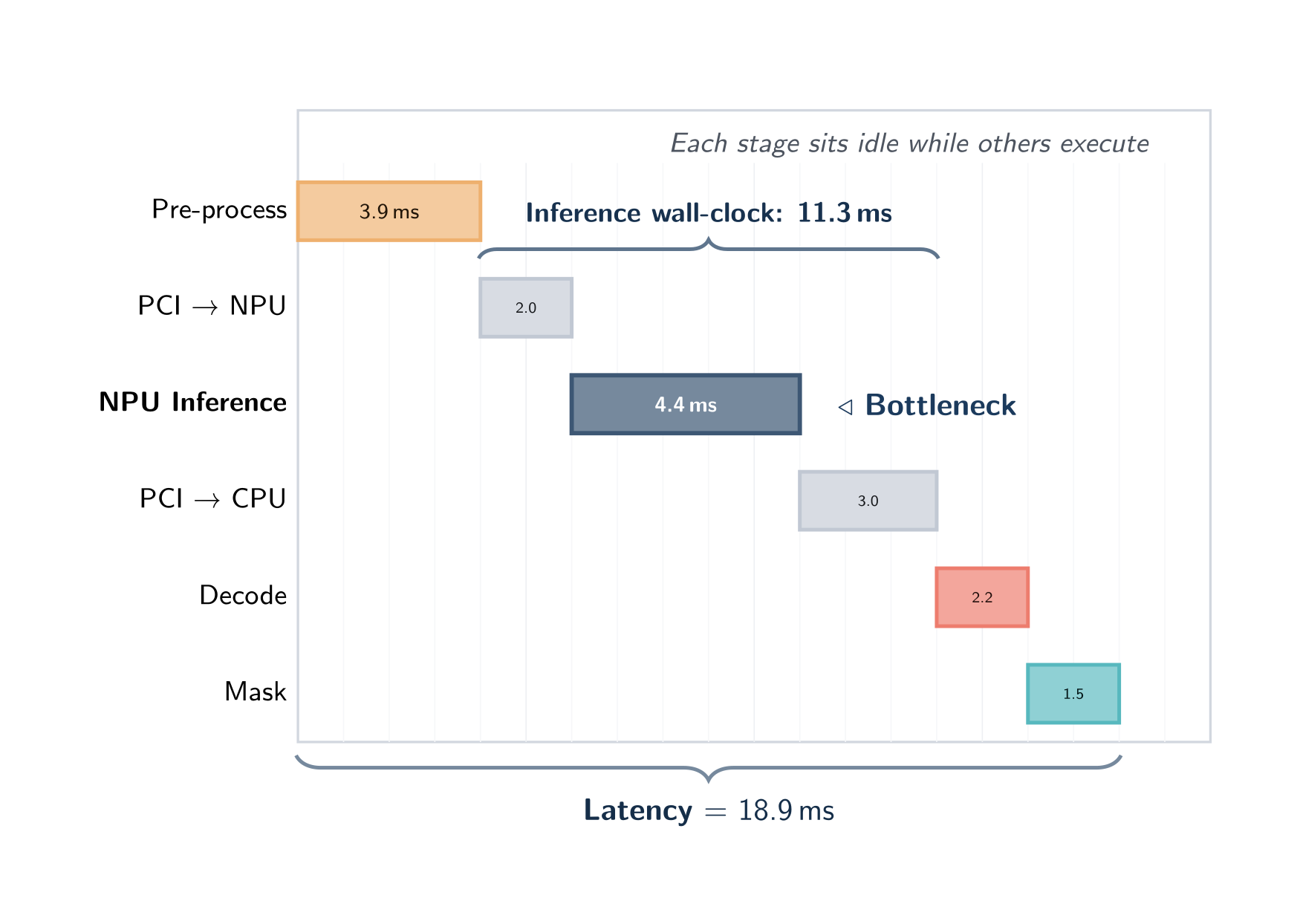
In this mode wall-clock latency equals the sum of all stage times and throughput equals 1 / latency. Sequential mode is the cheapest configuration in memory and the easiest to reason about — every millisecond of wall-clock time is attributable to exactly one stage.
Use sequential mode when:
- You are measuring the pure inference latency of a model without confounding pipeline-overlap effects.
- You are diagnosing which stage is the bottleneck — sequential timing is the cleanest reference.
- The platform's backend supports only depth 1 (see the table below) — the profiler clamps automatically and reports the resolved mode at run start.
Pipelined execution (Auto depth, default)
With depth ≥ 2 multiple frames are in flight through the pipeline at once: while one frame is in inference, the next frame is being preprocessed, the previous frame is being postprocessed, and so on. Every stage can be active simultaneously on different frames, and the slowest stage sets the throughput floor:
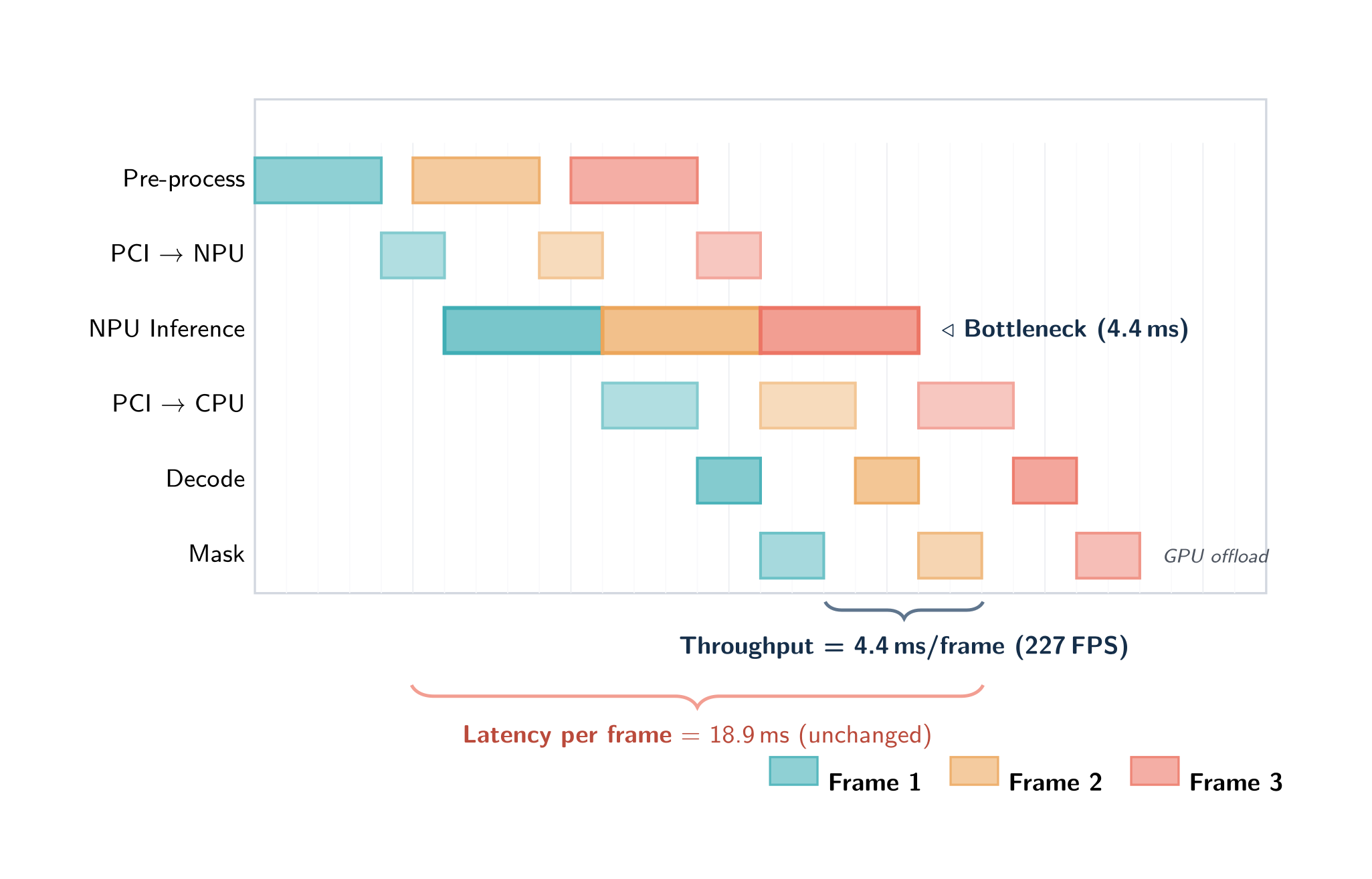
The important property: pipelining does not reduce the latency of any single frame — that critical path is unchanged. It increases throughput by converting "sum of stage times per frame" into "max of stage times per frame". For deployment profiling on real workloads the throughput number is almost always the more useful one.
Starting in 1.5.0 the default inference depth is Auto — the profiler selects the depth that best matches the detected backend and platform rather than using a fixed value of 2. Higher depths give more overlap headroom (useful when stage durations are uneven) at the cost of memory — each additional slot keeps another in-flight frame's worth of buffers alive. Passing --inference-depth N always overrides the auto value.
Backend auto-depth table
Each inference backend has an auto-selected inference depth determined by how many concurrent inference slots the hardware can serve efficiently. The profiler applies this default at startup unless overridden by --inference-depth:
| Backend | Auto inference depth | Notes |
|---|---|---|
| ONNX Runtime CPU | 2 | Generic default |
| ONNX Runtime CUDA (x86_64 Linux) | 4 | Also sets preprocess depth to 1 |
| ONNX Runtime CoreML GPU (macOS) | 3 | Measured knee at depth 3 |
| ONNX Runtime CoreML ANE / CPU (macOS) | 2 | ANE serializes internally |
| TensorRT (Jetson Orin) | device max | Full slot count auto-selected |
| TFLite XNNPACK | 2 | |
| TFLite Neutron (i.MX 95, DMA-BUF zero-copy) | 1 | Single-bind delegate; preprocess forced to 1 |
| TFLite Neutron (i.MX 95, CPU-staging) | 4 | Multiple independent slots (up to 4) |
| TFLite VxDelegate (i.MX 8M Plus VSI NPU) | 1 | Only one in-flight inference |
| Ara240 (Kinara, i.MX 95) | 8 | I/O rebind pool; NPU ceiling ≈249 FPS YOLOv8n |
| HailoRT (Hailo-8 / 8L) | device max |
The VSI NPU on the i.MX 8M Plus serves only one inference client at a time, so on that target the profiler runs as sequential regardless of what the user requests.
Per-stage depth flags
1.5.0 exposes independent concurrency controls for every pipeline stage. Each flag defaults to 0 (Auto):
| Flag | Controls | Default (Auto) |
|---|---|---|
--capture-depth N |
Parallel file-load / JPEG decode threads | 1 |
--preprocess-depth N |
Parallel preprocess workers (CPU + DMA; GPU/OpenGL-accelerated where available) | 1 in DMA-BUF zero-copy mode, 4 in CPU-staging mode |
--inference-depth N |
Concurrent in-flight inference slots | See backend table above |
--postprocess-depth N |
Parallel model decoder (DFL + NMS) threads | Auto based on CPU core count |
Setting any flag to 0 restores Auto for that stage. Passing 1 is equivalent to serializing that stage. The auto resolution for each stage is printed at run start alongside the backend name.
Neutron — DMA-BUF zero-copy vs CPU-staging
The Neutron delegate on i.MX 95 operates in two distinct modes depending on kernel support:
DMA-BUF zero-copy mode (kernel patch present, or NEUTRON_ENABLE_ZERO_COPY=1): a single inference slot is bound directly to device memory. The preprocess stage serializes with inference — the trace viewer shows their slices touching back-to-back rather than overlapping, so the preprocess → inference critical path behaves more like depth 1 than depth 2. Capture and postprocess still overlap freely and throughput still benefits from pipelining across those stages. Auto inference depth is 1; preprocess is forced to 1.
CPU-staging mode (kernel patch absent, or NEUTRON_ENABLE_ZERO_COPY=0): up to 4 independent inference slots run in parallel, each staging its input through system memory before dispatch. Auto inference depth is 4, delivering approximately 97 FPS on YOLOv5n at 640 on i.MX 95 Pro (single-slot baseline ≈73 FPS). The profiler detects the mode automatically and falls back cleanly if DMA-BUF is unavailable. At depth 4 or above the launch-time dialog warns that the mode is CPU-staging.
Launch-time Customize dialog
Every run started from the TUI (F4 Start, Studio Validate, local profiling) opens a launch modal before the pipeline starts. For ONNX models the dialog also selects the execution provider.
- Press Enter to launch immediately with Auto depths.
- Press c to open four sliders (Capture, Preprocess, Inference, Postprocess), each defaulting to Auto and showing what Auto will resolve to for the detected platform.
- Drag a slider to 1–8 to pin that stage; this is equivalent to passing the corresponding
--<stage>-depth Nflag. - The dialog displays a warning banner when the platform constrains a stage to single-thread concurrency (for example, VxDelegate inference or Neutron DMA-BUF preprocess).
How pipelining appears in the trace viewer
Open the Perfetto trace for any validation session in Studio (the Profile tab on the session card). At depth ≥ 2 you will see frames overlapping across the stage tracks — the same picture as the overlap diagram above, but with real timing.
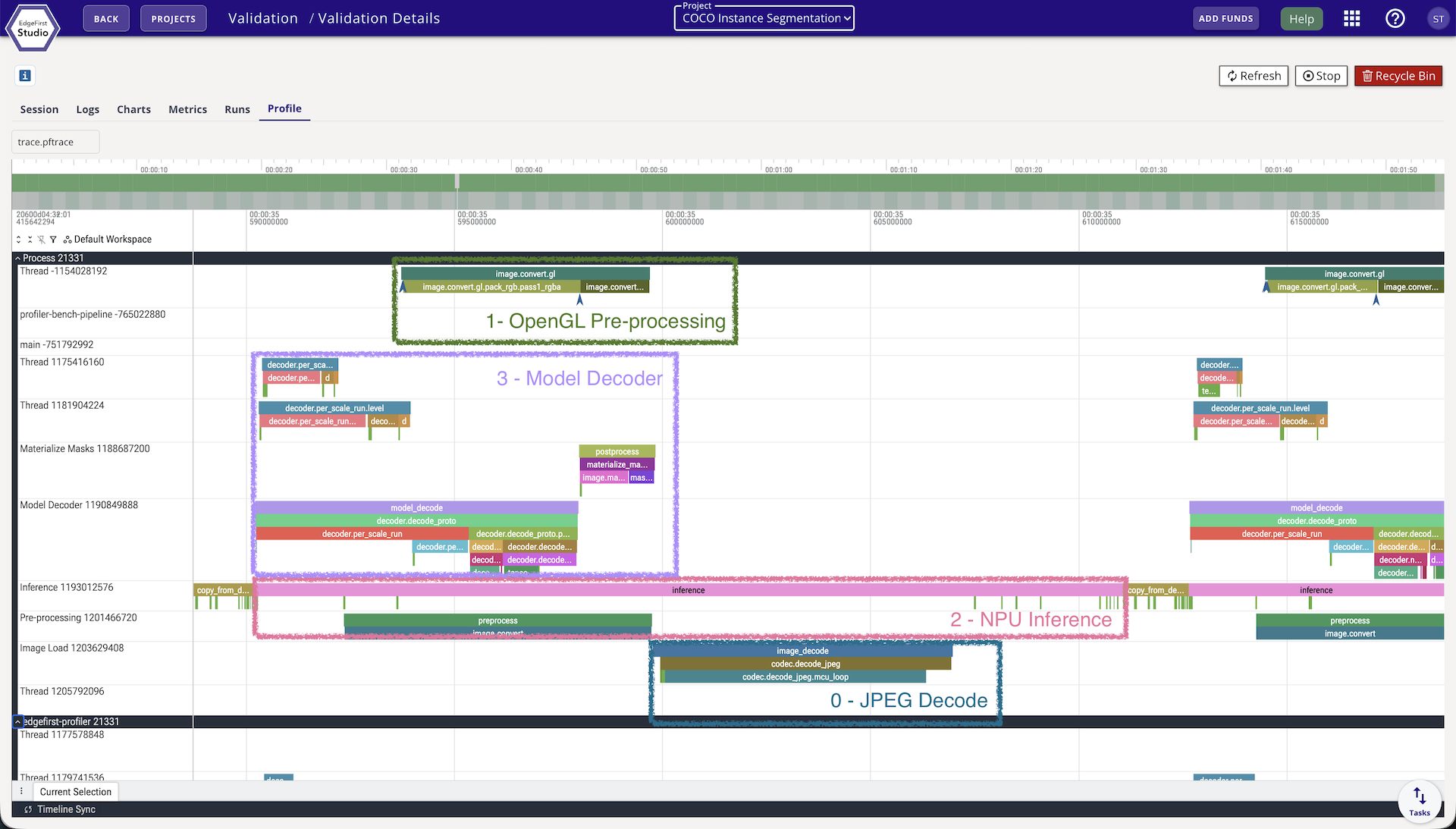
The four overlays on the trace above map directly to the pipeline stages, with each box covering a different frame in flight at the same instant:
- 0 — Capture: the CPU decoder reading the next image file off disk.
- 1 — OpenGL Pre-processing: hardware-accelerated resize / color-convert / quantize via
edgefirst-hal, writing into the input tensor. - 2 — NPU Inference: the accelerator running
invoke()on the already-preprocessed frame from the previous slot. - 3 — Model Decoder: postprocessing (box decode, NMS, mask decode) of the frame whose inference just completed.
Reading vertically at any point on the time axis shows what the profiler is doing concurrently — four frames in different stages of completion. Reading horizontally along any one track shows how that stage performs on consecutive frames.
At depth 1, all stage tracks line up sequentially per frame: the next frame's capture slice does not start until the previous frame's last stage finishes.
Multi-slot ONNX traces. When --inference-depth is greater than 1 on ONNX Runtime, the trace shows one track per inference slot (ort.run.slot0, ort.run.slot1, …) with true wall-clock positions, making real overlap between concurrent inferences directly visible.
Per-frame identity. Every pipeline stage span now carries the image_name and frame_id it processed, so clicking any span in the trace viewer immediately identifies which image produced it.
frame_e2e events. A frame_e2e event is emitted when each frame's result is ready. It carries the end-to-end work-time — the sum of that frame's own stage durations — which is the figure reported in the Session Report. Work-time is stable under varying pipeline depth; it does not balloon with queue backlog the way the raw capture→result wall-clock sojourn does in pipelined mode.
pipeline_config event. A single pipeline_config event at the start of the run records the full pipeline geometry: backend, execution provider, resolved depths for all four stages, and the Neutron mode when applicable.
A common diagnostic flow:
- Run once at the platform's auto depth.
- Compare end-to-end throughput (
Session Report) against the inference-only mean. - If throughput is much lower than
1 / inference_mean, the bottleneck is on a CPU stage — switch to sequential mode (--inference-depth 1) to confirm which one, then look at capture (large images) or postprocess (low confidence threshold producing many candidates).
CLI
edgefirst-profiler validate --session-id v-XXXX --inference-depth 1
edgefirst-profiler validate --session-id v-XXXX --inference-depth 2
edgefirst-profiler validate --session-id v-XXXX --inference-depth 4 # auto-clamped to backend max
Per-stage overrides can be combined:
# Pin inference to 4 slots, let preprocess and postprocess stay on Auto
edgefirst-profiler validate --session-id v-XXXX --inference-depth 4
# Fully manual geometry for reproducible benchmarking
edgefirst-profiler validate --session-id v-XXXX \
--capture-depth 1 \
--preprocess-depth 1 \
--inference-depth 1 \
--postprocess-depth 1
The resolved per-stage depths, the backend, and the operating mode (pipelined vs sequential) are reported once at run start, and recorded in the pipeline_config trace event for the session.
See also
- i.MX 8M Plus — Inference depth — the VSI delegate's auto-clamp to depth 1.
- Validation from Studio — Session Report — the per-stage timing breakdown printed to stdout on completion.