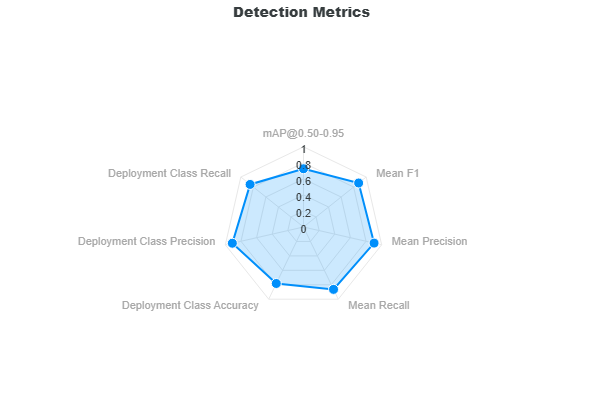
Object Detection Metrics
This section describes the validation metrics reported for Object Detection Validation. The object detection metrics are based on IoU which measures how closely the predictions aligns with the ground truth annotations. For object detection, the IoU is calculated from bounding boxes. However, for instance segmentation, the IoU is calculated from instance masks. The methods for computing object detection and instance segmentation metrics are the same. The object detection metrics are categorized into Full-Curve Metrics and Deployment Metrics.
The Full-Curve Metrics assess the model performance across varying score and IoU thresholds for all classes. The Deployment Metrics are based on the best model performance at the optimal score threshold.
Full-Curve Metrics
Full-Curve Metrics evaluate model performance across a wide range of confidence (score) and IoU (0.50-0.95) thresholds. To enable this, the NMS score threshold is set very low (e.g., 0.001), allowing nearly all predictions to be considered. The model is then evaluated over score thresholds from 0 to 1 and IoU thresholds from 0.50 to 0.95 to understand how performance changes as filtering becomes more or less strict.
The Full-Curve Metrics include:
- mean Average Precision (mAP)
- Mean Precision
- Mean Recall
- Mean F1 Score
Mean Average Precision (mAP)
Mean Average Precision (mAP) is one of the most important metrics for evaluating object detection models and is computed using the same methodology as Ultralytics (YOLO).
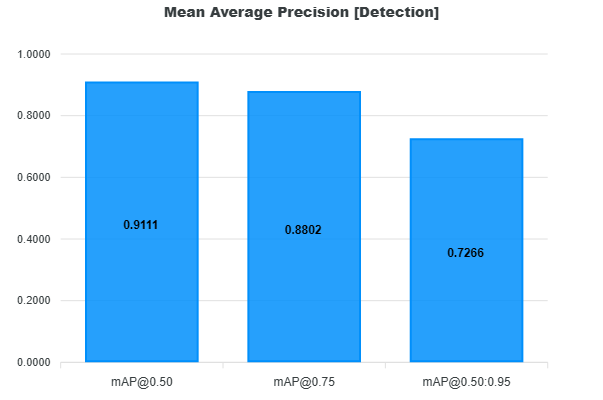
The mAP measures how well the model balances precision and recall across confidence thresholds, while also evaluating detection quality at different IoU thresholds.
Definitions
- Precision: Fraction of predicted objects that are correct
- Recall: Fraction of ground truth objects that are detected
- AP (Average Precision): Area under the Precision–Recall curve for a given class and IoU threshold
- mAP (mean AP): Mean of AP values across all classes
How mAP is computed
For a fixed IoU threshold, compute the AP (average precision):
- Predictions are sorted by confidence score
- Precision and recall are computed cumulatively
- A Precision–Recall curve is generated by sweeping the confidence (score) threshold from 0 to 1 at this IoU threshold
- AP is computed as the area under this curve
Note
IoU does not create the curve — it defines what counts as a true positive at each fixed threshold. For mAP@0.50:0.95, this AP computation is repeated over IoU thresholds from 0.50 to 0.95 and then averaged.
For each class:
- Compute AP at each IoU threshold
- For mAP@0.50:0.95, average AP across all IoU thresholds
- Then average across all classes
We report mAP at IoU thresholds (0.50, 0.75, 0.50-0.95):
- mAP@0.50
- Lenient matching (IoU ≥ 0.50)
- Focuses on detection correctness
- mAP@0.75
- Stricter matching
- Requires better localization
- mAP@0.50:0.95 (COCO metric)
- Average AP across IoU thresholds from 0.50 to 0.95 (step 0.05)
- Evaluates both detection and localization quality
F1 Score
The Mean F1 Score is the harmonic mean between precision and recall used to determine the model’s optimal score threshold. It is derived from the F1 vs Confidence curve, which shows how the F1 score changes as the score threshold varies. The model's optimal score threshold is at the max F1 score of this curve.
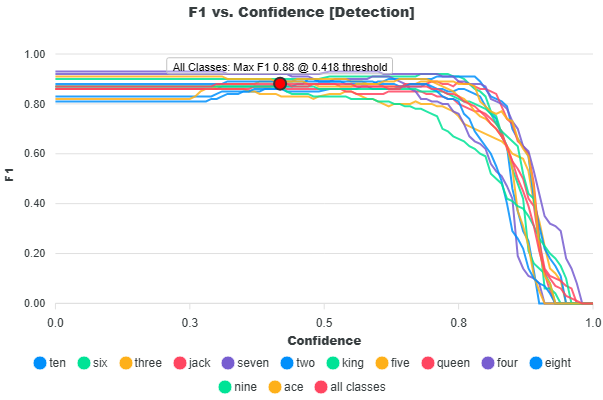
For each confidence threshold:
- Precision and recall are computed per class
- The F1 score is calculated as the harmonic mean:
Note
The equations for precision and recall are provided in the glossary.
The optimal score threshold is selected as the point where the mean F1 score across all classes is maximized:
The reported Mean F1 score is the average of per-class F1 values at this optimal threshold:
The Mean F1 score represents the best balance between precision and recall and defines the recommended operating score threshold for deploying the model.
Mean Precision
This metric is defined as the average of the per-class precision values at the optimal threshold where the mean F1 score is highest. This score reflects the overall ability of the model to avoid false positives across all classes.
At the selected threshold:
- Precision is obtained for each class
- The values are averaged:
Note
The equation for precision is provided in the glossary.
The Mean Precision metric measures how accurate the model’s predictions are at the optimal threshold. A high precision score indicates fewer false positives.
Mean Recall
This metric is defined as the average of the per-class recall values at the threshold where the mean F1 score is highest. This score reflects the model’s ability to find all relevant objects (true positives) across all classes.
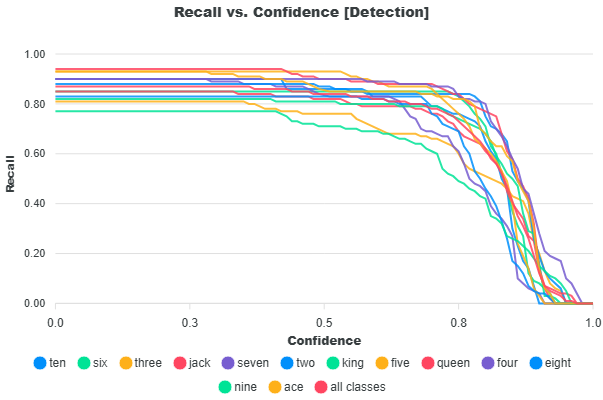
At this threshold:
- Recall is obtained for each class
- The values are averaged:
Note
The equation for recall is provided in the glossary.
The Mean Recall metrics measures how well the model detects ground truth objects. A high recall score indicates fewer missed detections.
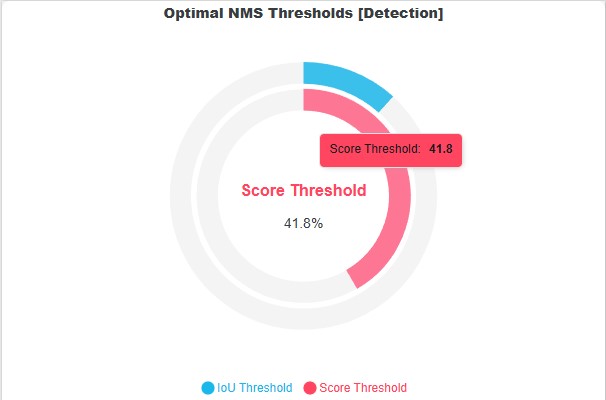
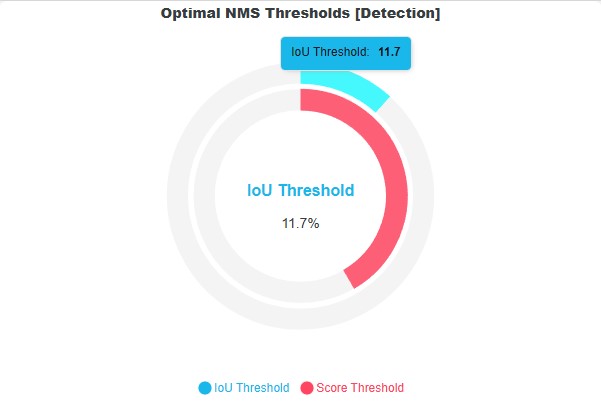
Optimal Thresholds
| Optimal Score Threshold | Optimal IoU Threshold |
|---|---|
 |
 |
The optimal thresholds are the estimated values to use for deploying the model to achieve the highest performance accuracy based on the validation dataset. As mentioned, the score threshold is calculated based on the highest F1 score across all classes under the F1 versus Confidence curve. For more information, refer to the F1 Score section.
The optimal IoU threshold is determined directly from the validation dataset using a data-driven approach. Note that the IoU threshold is an NMS parameter that defines when two prediction boxes are considered duplicates based on their overlap. Lower IoU thresholds make suppression more aggressive (even small overlaps are removed), while higher thresholds allow more overlapping predictions to remain.
To estimate a suitable IoU threshold, IoU values are computed between bounding boxes in the ground truth dataset. These values represent the natural overlap that occurs in the data. The highest overlaps in the ground truth dataset are also expected to exist in the model predictions, so we frame the optimal IoU threshold to also allow the higher overlaps as seen in the dataset. Instead of simply taking the maximum overlap (which may be an outlier), the method applies Tukey’s boxplot rule to derive a robust upper bound.
Specifically:
- The first (25th percentile) quartile (Q1), median, and third (75th percentile) quartile (Q3) of the IoU distribution are computed
- The interquartile range (IQR) is defined as $$ \text{IQR} = Q_3 - Q_1 $$
- The upper whisker (optimal IoU) is calculated as:
What if the dataset does not have any ground truth intersections?
In some datasets, there may be no overlapping ground truth bounding boxes, meaning it is not possible to estimate an optimal IoU threshold using the IoU distribution of ground truth intersections. In this case, a fallback strategy is used to choose the IoU threshold that eliminates the highest number of localization false positives (duplicate predictions). Note that the localization false positives are any predictions not matched to any ground truth primarily due to prediction duplications (not filtered by NMS) or it does not intersect any ground truth bounding box.
The IoU values for these localization false positives are then collected. These IoU values represent the duplicated boxes that should have been filtered by NMS. The IoU values of these false positives are then grouped into a histogram. The optimal IoU threshold is then selected as the lower edge of the bin with the highest frequency. In other words, if there are no ground truth intersections, the bin with the most number of localization false positive is taken as the optimal IoU threshold.
What if there are no false positives?
If no false positives are present, or if the computed optimal IoU threshold is 0, the system falls back to report the default NMS IoU threshold of 0.70, which is consistent with the Ultralytics default.
Deployment Metrics
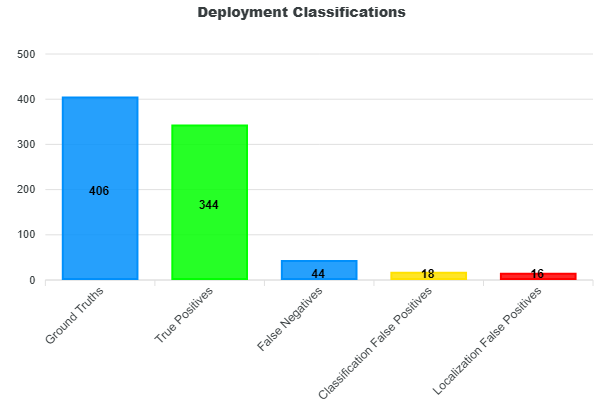
As mentioned, the Full-Curve Metrics assess the model performance at varying NMS score thresholds to find the optimal score threshold that yields the max F1-score. This score threshold is then used to filter the predictions. These filtered predictions are then classified into true positives, false positives (classification, localization), and false negatives.
Classifications
For more information on how these predictions are matched and classified into true positives, false positives, and false negatives, please see the Matching and Classification Rules.
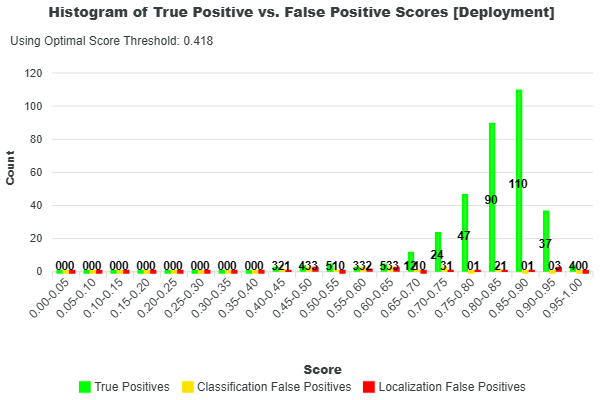
Additional insight into these classifications can be gained by examining the distributions of prediction scores and IoUs, shown in the histograms below. In both plots, green represents true positives, yellow represents classification false positives, and red represents localization false positives.
| Histogram of Scores | Histogram of IoUs |
|---|---|
 |
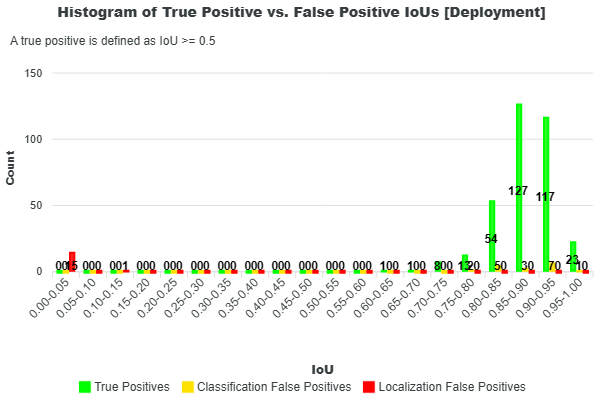 |
These histograms help reveal how different types of predictions are distributed. For example, a high number of false positives with high confidence scores may indicate issues with the model’s classification behavior or training data. Similarly, a concentration of predictions with low IoU values suggests poor localization, meaning predicted objects are not well aligned with the ground truth.
Further analysis can be performed using the Confusion Matrix, which breaks down prediction outcomes by class. This visualization highlights which classes the model detects well and which it frequently misses, potentially indicating a need for more training data for those classes. It also reveals common misclassifications between classes, helping identify areas that may require further investigation or improvements in the training dataset.
From these plots, the sum of true positives, false positives, and false negatives equals the totals reported in the deployment classifications. Every prediction is accounted for in this breakdown.
Lastly, the precision, recall, and accuracy scores of each class are provided in the Class Metrics bar chart. You can find the equations for precision, recall, and accuracy in the Glossary.
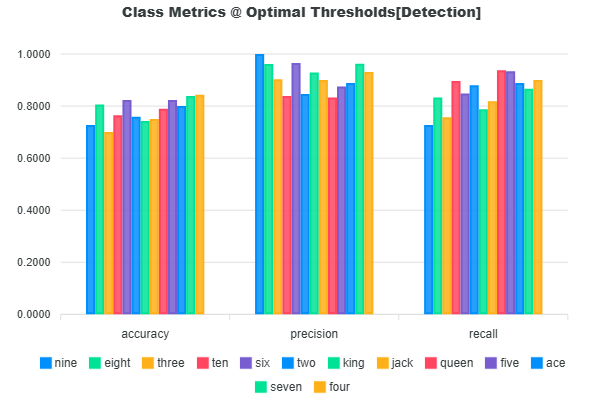
The deployment precision, recall, and accuracy are calculated based on the mean value of the precision, recall, and accuracy of each class as shown in the next sections.
Deployment Class Precision
The deployment class precision is the average of the precision values of each class.
Precision Equation
The equation for precision is shown in the Glossary.
Precision measures how well the model outputs correct predictions. Precision alone does not provide a final summary of the model performance because it only considers the ratio of the number of correct detections to the total number of detections. Consider a case where the model might have made 9 detections which are all correct and yields a precision of 100%, but there are 200 ground truth annotations, the model missed the rest of the 191 annotations which yields a recall of 4.5%.
Deployment Class Recall
The deployment class recall is the average of the recall values of each class.
Recall Equation
The equation for recall is shown in the Glossary.
Recall measures how well the model finds the ground truth annotations. This metric only considers the ratio of correct detections against the total number of ground truths. However, it is possible that the model will correctly find all ground truth annotations, but it might have generated large amounts of localization false positives.
Deployment Class Accuracy
The deployment class accuracy is the average of the accuracy values of each class.
Accuracy Equation
The equation for accuracy is shown in the Glossary.
This accuracy metric provides a better representation of the overall model performance over precision and recall. The accuracy metric aims to combine both precision and recall by considering correct detections (TP), false detections (localization FP and classification FP), and missed detections (FN). The accuracy is the ratio of the correct detections against all model detections and all ground truth objects. This metric aims to measure how well the model aligns its detections to the ground truth and a perfect alignment suggests zero missed annotations and zero false detections.
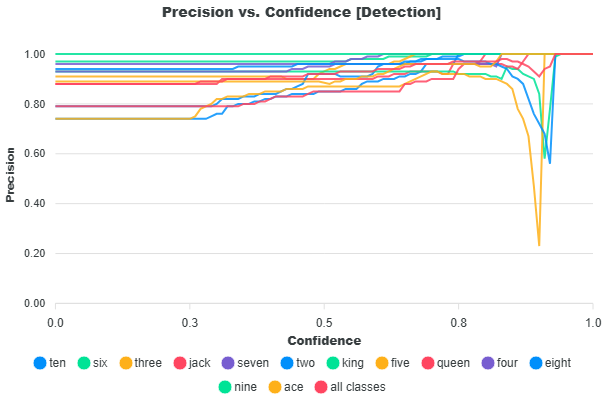
Precision versus Recall
According to Mariescu-Istodor and Fränti (2023), “The performance is a trade-off between precision and recall. Recall can be increased by lowering the selection threshold to provide more predictions at the cost of decreased precision.” In EdgeFirst Studio, this selection threshold corresponds to the score threshold used in Non-Maximum Suppression (NMS), which filters detections based on their confidence scores.
Lowering the score threshold allows more detections to pass through, increasing the likelihood of identifying ground truth objects (higher recall), but also introducing more incorrect predictions (lower precision). Increasing the threshold has the opposite effect: it filters out more detections, improving precision while potentially missing true objects and reducing recall.
The Precision–Recall curve illustrates this trade-off across different threshold values. At lower thresholds, the model produces more detections, resulting in higher recall but lower precision. As the threshold increases, precision improves due to stricter filtering, while recall decreases as fewer detections are retained. The curve below shows this relationship for each class in the dataset, along with the average across all classes. A larger area under the curve indicates better overall performance, reflecting a stronger balance between precision and recall across thresholds.
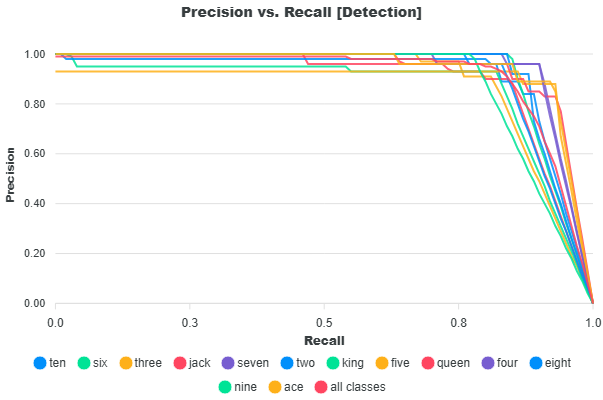
Precision and recall are common metrics used for evaluating object detectors in machine learning. According to Mariescu-Istodor and Fränti (2023), "Precision is the number of correct results (true positives) relative to the number of all results. Recall is the number of correct results relative to the number of expected results" (p.1). In this case interpreting "all results" as the model's detection results and "expected results" as the ground truth in the dataset - precision is defined as the fraction of correct detections out of the total detections, and recall is defined as the fraction of correct detections out of the total ground truth.
Taking from Vignesh-Babu (2020) and Padilla, Passos, Dias, Netto, & Da Silva (2021), the equation for precision and recall is defined as the following.
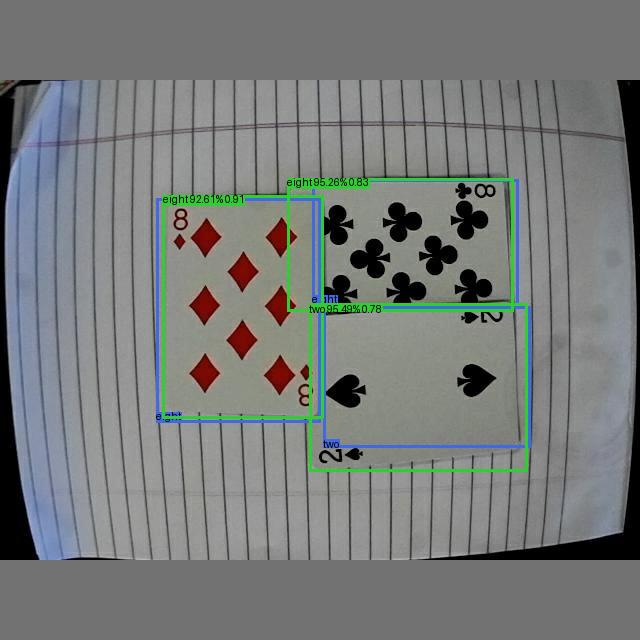
However, on the account of the EdgeFirst Studio's method of classifying detections where false positives are further categorized into localization and classification false positives, then the total number of detections is really the sum of true positives, classification false positives, and localization false positives. The total number of ground truths is the sum of true positives, false negatives, and classification false positives as shown in the resulting image below.

In this image there are two true positives (green), one false negative (blue), one classification false positive (red), and four ground truth objects (blue). To agree with the definition of recall being the fraction of all correct detections over all ground truths, the number ground truth becomes the sum of true positives, false negatives, and classification false positives. The formulas are thus adjusted in the following way which is implemented in EdgeFirst Studio.
Confusion Matrix
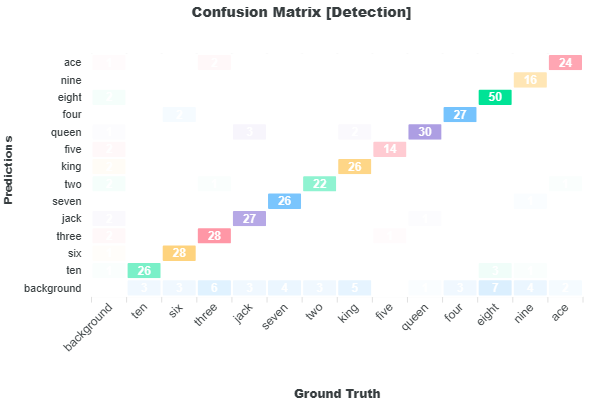
The Confusion Matrix provides a comparison between the ground truth and the prediction labels which gives an indication of how closely the model predictions matches the ground truth and the areas where it diverges. The Confusion Matrix tracks the counts of each ground truth and prediction label. These counts are based on the deployment metrics counts of true positives, false positives, and false negatives. In this representation of the matrix, the ground truth labels are placed along the x-axis and the prediction labels along the y-axis. Along the diagonal where both prediction and ground truth label matches, you can find the number of true positives of the specific label. The sum of the values along the diagonal equals the number of true positives presented in the deployment metrics. The first column where the ground truth label is "background" is the number of localization false positives where a model makes a false prediction of objects that are not present in the image. The sum of the first column equals the number of localization false positives in the deployment metrics. The last row where the prediction label is "background" is the number of false negatives where the model missed to detect these labels in the image. The sum of the last row equals the number of false negatives in the deployment metrics. Throughout the matrix, you may see counts for mismatching labels. The label mismatches represents the classification false positives and its sum equals the number of classification false positives in the deployment metrics.
Sample Computation
Let's take a closer look at how metrics are computed based on the following example. In this example, there are three ground truth boxes, three true positives (green) and two localization false positives (red). There are five predictions in total.
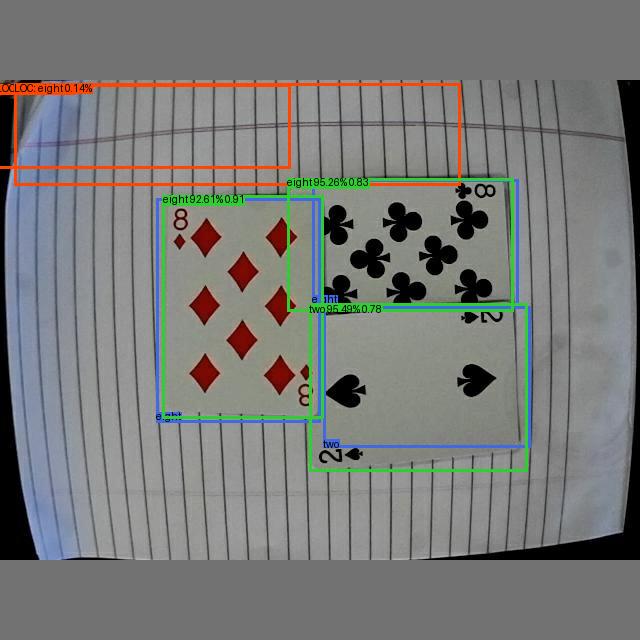
Predictions
| Pred | Index | Labels | Scores |
|---|---|---|---|
| 0 | 5 | "two" | 0.9549317 |
| 1 | 10 | "eight" | 0.95256793 |
| 2 | 10 | "eight" | 0.92612094 |
| 3 | 10 | "eight" | 0.00142229 |
| 4 | 10 | "eight" | 0.00137654 |
Ground Truth
| GT | Index | Labels |
|---|---|---|
| 0 | 10 | "eight" |
| 1 | 10 | "eight" |
| 2 | 5 | "two" |
The final calculated Full-Curve Metrics for this sample are as follows:
+--------------------------------------------------+
| DETECTION METRICS |
+--------------------------------------------------+
| Ground Truths: 3 |
| Predictions: 5 |
+---------------+-------------------+--------------+
| | Mean Precision | 99.13 |
| | mAP@0.5 | 99.5 |
| Precision (%) | mAP@0.75 | 99.5 |
| | mAP@0.5-0.95 | 67.79 |
+---------------+-------------------+--------------+
| Recall (%) | Mean Recall | 100.0 |
+---------------+-------------------+--------------+
| F1 Score (%) | Mean F1 | 99.56 |
+---------------+-------------------+--------------+
The final calculated Deployment Metrics for this sample are as follows:
+--------------------------------------------------+
| DEPLOYMENT METRICS @ OPTIMAL THRESHOLDS |
+---------------+----------------+-----------------+
| Ground Truths | True Positives | False Negatives |
+---------------+----------------+-----------------+
| 3 | 3 | 0 |
+-------------------------+------------------------+
| Classification FP | Localization FP |
+-------------------------+------------------------+
| 0 | 0 |
+-------------------------+------------------------+
| Overall Accuracy | 100.0 |
| Mean Class Accuracy | 100.0 |
+-------------------------+------------------------+
| Overall Precision | 100.0 |
| Mean Class Precision | 100.0 |
+-------------------------+------------------------+
| Overall Recall | 100.0 |
| Mean Class Recall | 100.0 |
+-------------------------+------------------------+
Sorted Predictions
The predictions are always sorted based on highest confidence first to lowest.
-
The batch IoU is calculated between the ground truth and the predictions
GT \ Pred Pred 0 Pred 1 Pred 2 Pred 3 Pred 4 GT 0 0.0044969902 0.82639343 0.02061883 0.0000000 0.013678555 GT 1 0.017273406 0.05893239 0.91331422 0.0000000 0.0000000 GT 2 0.77907538 0.017573632 0.00063108001 0.0000000 0.0000000 -
Only the prediction labels that matches the ground truth labels are considered
- Correct Classes
GT \ Pred Pred 0 "two" Pred 1 "eight" Pred 2 "eight" Pred 3 "eight" Pred 4 "eight" GT 0 "eight" False True True True True GT 1 "eight" False True True True True GT 2 "two" True False False False False - IoU Matrix
GT \ Pred Pred 0 Pred 1 Pred 2 Pred 3 Pred 4 GT 0 0.0 0.8263934 0.02061883 0.0 0.01367856 GT 1 0.0 0.05893239 0.9133142 0.0 0.0 GT 2 0.7790754 0.0 0.0 0.0 0.0 -
Build the correct matrix
The correct matrix is a n x 10 matrix where n represents the number of predictions and 10 represents the IoU thresholds from 0.50 to 0.95 in 0.05 intervals. The correct matrix tracks whether each prediction remains as a true positive as the threshold increases.
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 (0.7790754 IoU) True True True True True True False False False False Pred 1 (0.8263934 IoU) True True True True True True True False False False Pred 2 (0.9133142 IoU) True True True True True True True True True False Pred 3 (0.0 IoU) False False False False False False False False False False Pred 4 (0.01367856 IoU) False False False False False False False False False False -
Gather the true positives and false positives for each class
Here we iterate through each unique ground truth class [5, 10].
Accumulative Matrix
The following matrices accumulates after each row (each prediction).
- If the correct matrix is True, we add +1 to the current number of true positives in the subsequent row, but the number of false positives remains unchanged.
- Otherwise if the correct matrix is False, we add +1 to the current number of false positives in the subsequent row, but the number of true positives remains unchanged.
-
Class 5
There's only one prediction with the class 5, this is the first prediction
i = [ True, False, False, False, False]. There's one prediction with this classn_p = 1and one ground truth with this classn_l = 1.True Positive Counts (TPC)
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 1 1 1 1 1 1 0 0 0 0 False Positive Counts (FPC)
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 0 0 0 0 0 0 1 1 1 1 -
Class 10
There are four predictions with the class 10,
i = [ False, True, True, True, True]. There's four prediction with this classn_p = 4and two ground truth with this classn_l = 2.True Positive Counts (TPC)
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 1 1 1 1 1 1 1 1 0 0 0 Pred 2 2 2 2 2 2 2 2 1 1 0 Pred 3 2 2 2 2 2 2 2 1 1 0 Pred 4 2 2 2 2 2 2 2 1 1 0 False Positive Counts (FPC)
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 1 0 0 0 0 0 0 0 1 1 1 Pred 2 0 0 0 0 0 0 0 1 1 2 Pred 3 1 1 1 1 1 1 1 2 2 3 Pred 4 2 2 2 2 2 2 2 3 3 4
-
Compute the precision and recall for each class
The formulas for precision and recall are as follows.
\[ \text{precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} \]\[ \text{recall} = \frac{\text{TP}}{\text{GT}_{\text{c}}} \]where \( \text{GT}_c \) is the number of ground truth instances for class \( c \).
Confidence Curves
- The precision vs confidence curve is based on the IoU threshold 0.50 then interpolated across 1000 data points
- The recall vs confidence curve is based on the IoU threshold 0.50 then interpolated across 1000 data points
- The F1 vs confidence curve is based on the IoU threshold 0.50 then interpolated across 1000 data points
-
Class 5
Precision per Prediction and IoU Threshold
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 Recall per Prediction and IoU Threshold
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 -
Class 10
Precision per Prediction and IoU Threshold
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 Pred 1 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.5 0.5 0.0 Pred 2 0.667 0.667 0.667 0.667 0.667 0.667 0.667 0.333 0.333 0.0 Pred 3 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.25 0.25 0.0 Recall per Prediction and IoU Threshold
Pred \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Pred 0 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.0 0.0 0.0 Pred 1 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.5 0.5 0.0 Pred 2 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.5 0.5 0.0 Pred 3 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.5 0.5 0.0
-
Compute the average precision (AP)
The average precision is computed across IoU thresholds 0.50 to 0.95 in 0.05 intervals. The average precision is calculated based on the area under the precision versus recall curve. This is an integration using the composite trapezoidal rule.
Average Precision (Discrete COCO / 101-point Interpolation)
\[ \text{AP} = \sum_{k=1}^{101} \text{precision}(r_k) \cdot \Delta r \]Average Precision (AP) per Class and IoU Threshold
Class \ IoU 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 Class 5 0.995 0.995 0.995 0.995 0.995 0.995 0.000 0.000 0.000 0.000 Class 10 0.995 0.995 0.995 0.995 0.995 0.995 0.995 0.31125 0.31125 0.000 Class 5
- Precision = 1.0 until IoU 0.75, then drops to 0
- Recall = 1.0 until IoU 0.80, then drops to 0
- AP ≈ 0.995 (slightly < 1 due to interpolation and discretization)
Class 10
- Multiple predictions → gradual precision decay
- Recall increases stepwise (0.5 → 1.0)
-
Compute final metrics
-
mAP@0.50
\[ mAP@0.50 = \frac{1}{C}\sum_{i=1}^{C}\text{AP@0.50}_{i}, \quad C = \text{number of classes} \]Substituting values:
\[ mAP@0.50 = \frac{0.995 + 0.995}{2} = 0.995 \]
-
mAP@0.75
\[ mAP@0.75 = \frac{1}{C}\sum_{i=1}^{C}\text{AP@0.75}_{i}, \quad C = \text{number of classes} \]Substituting values:
\[ mAP@0.75 = \frac{0.995 + 0.995}{2} = 0.995 \]
-
mAP@0.50–0.95
First compute the average AP across IoU thresholds for each class:
\[ \text{AP}_{0.50:0.95} = \frac{1}{10} \sum_{t=1}^{10} \text{AP}_{\text{IoU}_t}, \quad \text{where } \text{IoU}_t \in \{0.50, 0.55, \dots, 0.95\} \]Class-wise results:
\[ \text{AP}_{0.50:0.95}^{(5)} = \frac{6 * 0.995}{10} \]\[ \text{AP}_{0.50:0.95}^{(10)} = \frac{7 * 0.995 + 2 * 0.31125}{10} \]Then compute the final mean across classes:
\[ mAP@0.50-0.95 = \frac{1}{C}\sum_{i=1}^{C}\text{AP@0.50-0.95}_{i}, \quad C = \text{number of classes} \]\[ mAP@0.50-0.95 = \frac{\text{AP}_{0.50:0.95}^{(5)} + \text{AP}_{0.50:0.95}^{(10)}}{2} = 0.678 \] -
Mean Precision, Recall, F1
The precision and recall values from step 5 where interpolated across 1000 data points where the x-axis represents the prediction confidence scores and the y-axis is either precision or recall. The F1-score is then calculated using $$ \text{f1} = \frac{2 * precision * recall}{precision + recall} $$
The highest F1 score is at the score threshold
0.926. The precision, recall, and F1 score of each class at this threshold is as follows.Class \ Metric Precision Recall F1-Score Class 5 1.0 1.0 1.0 Class 10 0.98260945 1.0 0.99122845 The reported metrics for the Mean Precision, Recall, and F1 is the average across each class.
\[ \text{Mean Precision} = \frac{1.0 + 0.98260945}{2} = 0.9913 \]\[ \text{Mean Recall} = \frac{1.0 + 1.0}{2} = 1.0 \]\[ \text{Mean F1} = \frac{1.0 + 0.99122845}{2} = 0.9956 \]
The optimal score threshold found based on the highest F1 score is 0.926. To calculate the deployment metrics, we filter predictions based on scores greater than or equal to this threshold.
Filtered Predictions
| Pred | Index | Labels | Scores |
|---|---|---|---|
| 0 | 5 | "two" | 0.9549317 |
| 1 | 10 | "eight" | 0.95256793 |
| 2 | 10 | "eight" | 0.92612094 |
Ground Truth
| GT | Index | Labels |
|---|---|---|
| 0 | 10 | "eight" |
| 1 | 10 | "eight" |
| 2 | 5 | "two" |
-
Match predictions to ground truths by following the Matching and Classifications Rules
Based on the batch IoU, the following matches are made.
IoU Grid (GT vs Predictions)
GT \ Pred Pred 0 Pred 1 Pred 2 GT 0 0.0044969902 0.82639343 0.02061883 GT 1 0.017273406 0.05893239 0.91331422 GT 2 0.77907538 0.017573632 0.00063108001 - GT 0 => Pred 1
- GT 1 => Pred 2
- GT 2 => Pred 0
-
Gather classifications of true positives, false positives, and false negatives per class
In this sample, all predictions are regarded as a true positive since the labels matches the ground truth and the IoU >= 0.50 to be regarded as a true positive. Please see Object Detection Classifications for more information.
-
Calculate precision, recall, and accuracy per class
Class \ Classifications TP FN FP Class 5 1 0 0 Class 10 2 0 0 Class \ Metric Precision Recall Accuracy Class 5 1.0 1.0 1.0 Class 10 1.0 1.0 1.0 -
Calculate the deployment precision, recall, and accuracy
The deployment metrics are calculated as the average across all classes
Precision Recall Accuracy 1.0 1.0 1.0 1.0 1.0 1.0
Further Reading
This page has described the object detection metrics reported by EdgeFirst Studio. To better understand the rules set for matching model predictions to ground truth and classifying predictions into true positives, false positives, and false negatives see Matching and Classification Rules.
References
Fränti, P., & Mariescu-Istodor, R. (2023, March 1). Soft precision and recall. https://doi.org/10.1016/j.patrec.2023.02.005
Babu, G. V. (2021, December 13). Metrics on Object Detection - gandham vignesh babu - Medium. Retrieved from Metrics on Object Detection
Padilla, R., Passos, W. L., Dias, T. L. B., Netto, S. L., & Da Silva, E. A. B. (2021, January 25). A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit | MDPI
Blogger, T. (2023, November 7). Mean Average Precision (mAP): Definitions & Misconceptions | Medium. Retrieved from Mean Average Precision (mAP): Common Definitions, Myths & Misconceptions