Dataset Management
This page will provide tutorials for managing datasets in EdgeFirst Studio.
View Dataset
This tutorial will show how to open the gallery of the dataset to see the individual samples in the dataset.
From the "Projects" page, you can click on the dataset button indicated in red to view the datasets contained in the project.
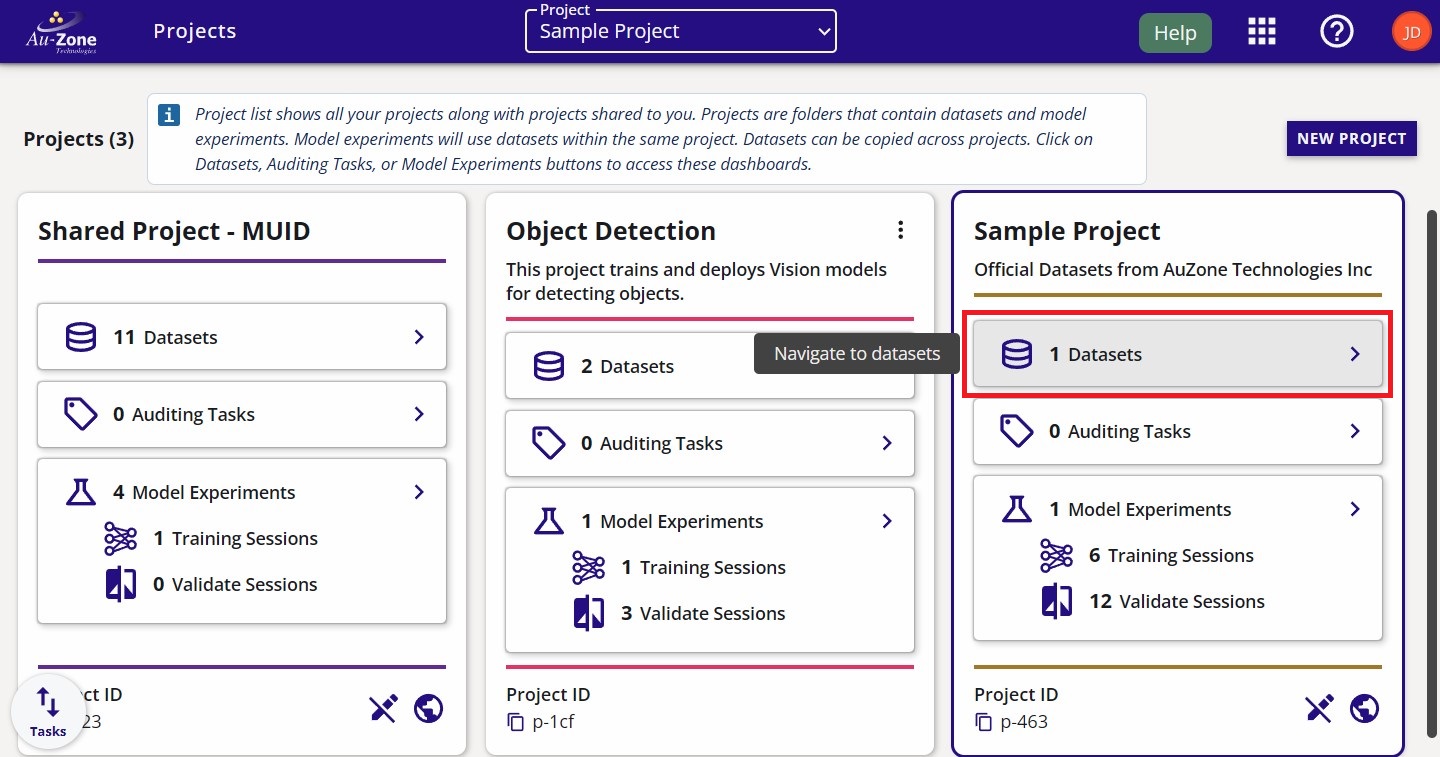
You will now see the datasets contained in the project. Each dataset has a gallery.

This dataset has a total of 1399 images and single label "coffeecup". It has two partitions; "train" and "val". There is a total of 1119 images for the training group ("train") and 280 images for the validation group ("val").
Click the image preview to view the dataset gallery. The dataset gallery will look like the following below.
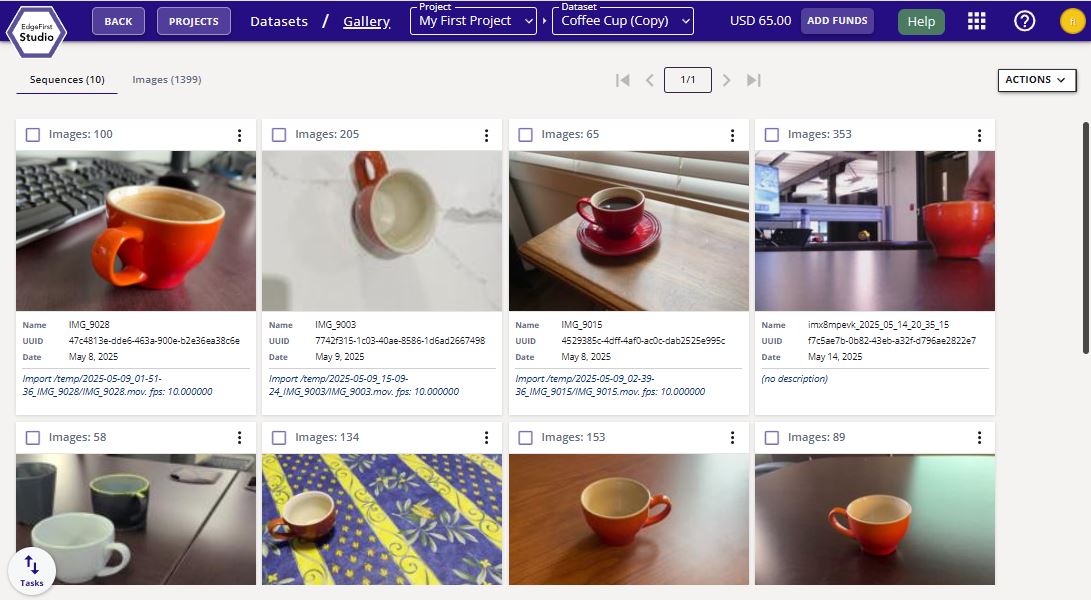
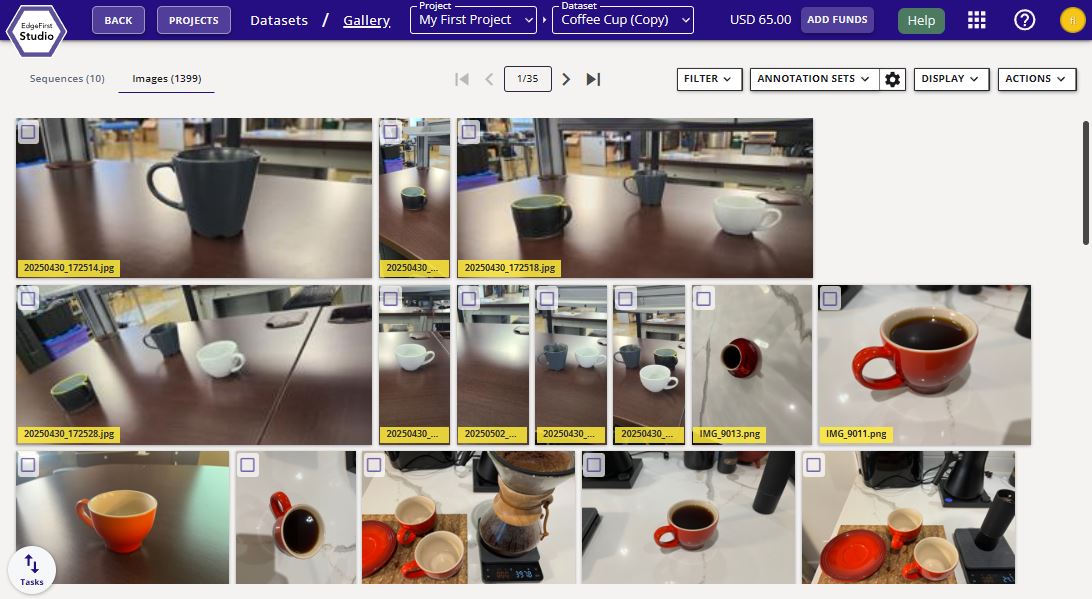
This dataset will contain both sequences (videos) and images. Clicking on the sequences will provide video playback of the sequence. Otherwise, clicking on images will expand the image view and allow playback of all images in the dataset.
This dataset has a complete set of 2D annotations (masks and bounding boxes) of coffee cups.
Fast Annotations
This dataset was quickly annotated using the Automatic Ground Truth Generation (AGTG) feature of EdgeFirst Studio.
Edit Dataset Information
The dataset name and description can be edited by clicking on the dataset extended menu on the top right portion of the dataset card. This should bring up the options and "Edit Info" as the first in the list. Click on "Edit Info".
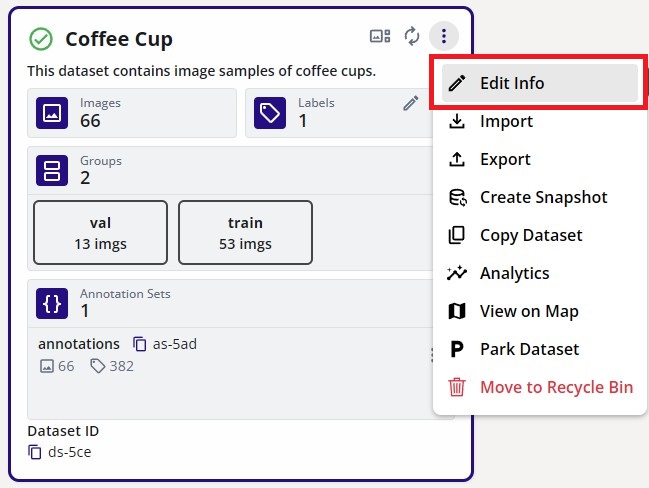
This will bring up the window to edit the dataset "Name" and the "Description". Once the changes are made, click "Apply Changes" to save the changes.
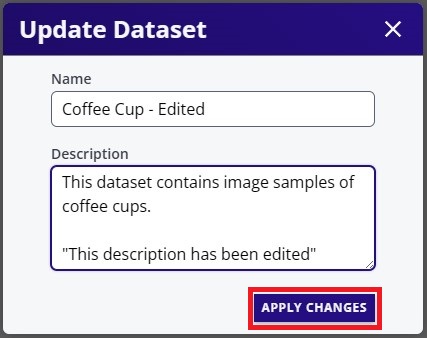
The changes should appear on the dataset card as shown below.
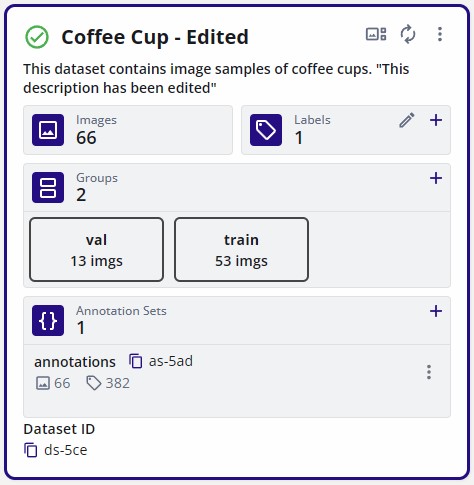
View Fusion Dataset
This tutorial will show an example of a dataset that is ready for training.
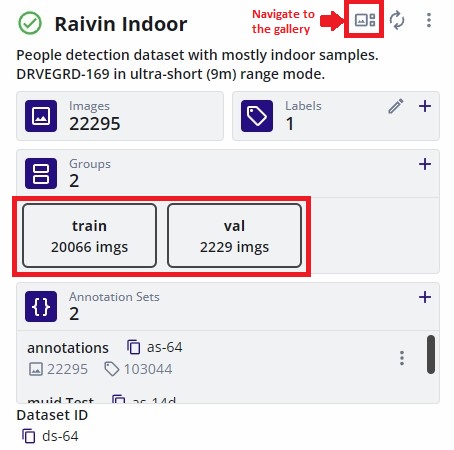
Verify that the dataset has a training and validation split. The sample dataset shown below has a dedicated split for training (20066 samples) and validation (2229 samples).
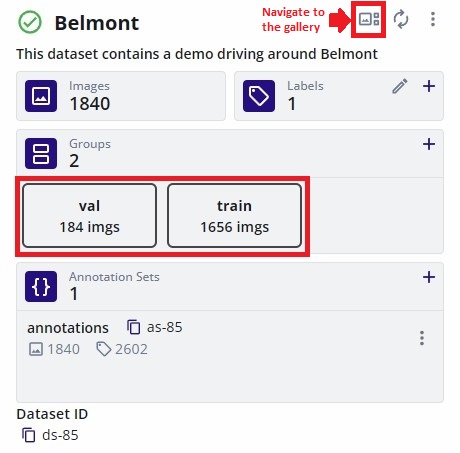
Another sample dataset shown below is for training Vision models which has a dedicated split for training (1656 samples) and validation (184 samples).
Verify the contents of the dataset and the annotations. Click the button that navigates to the gallery. This will show the contents of the dataset. The dataset may be comprised of multiple sequences as shown below.
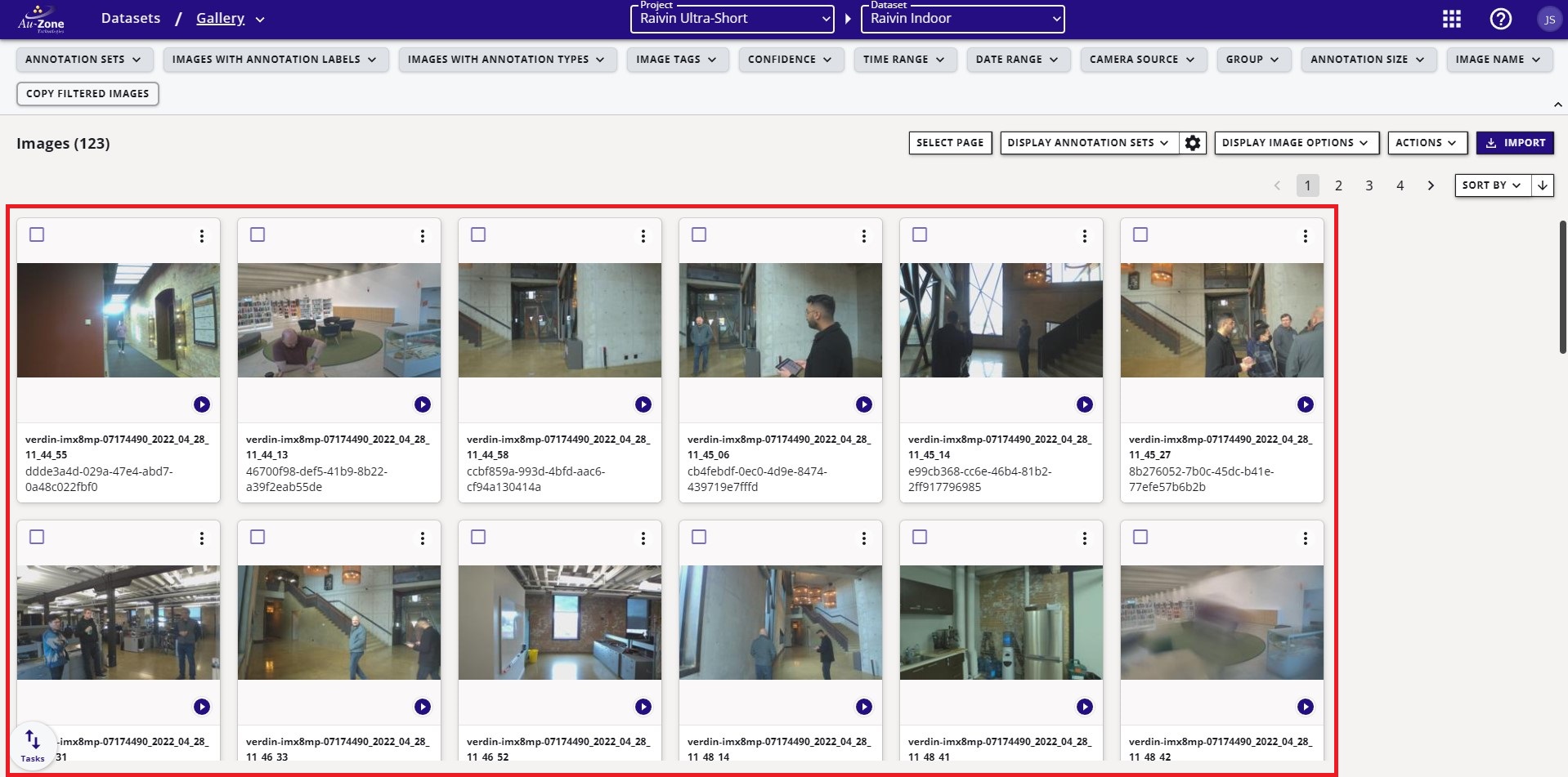
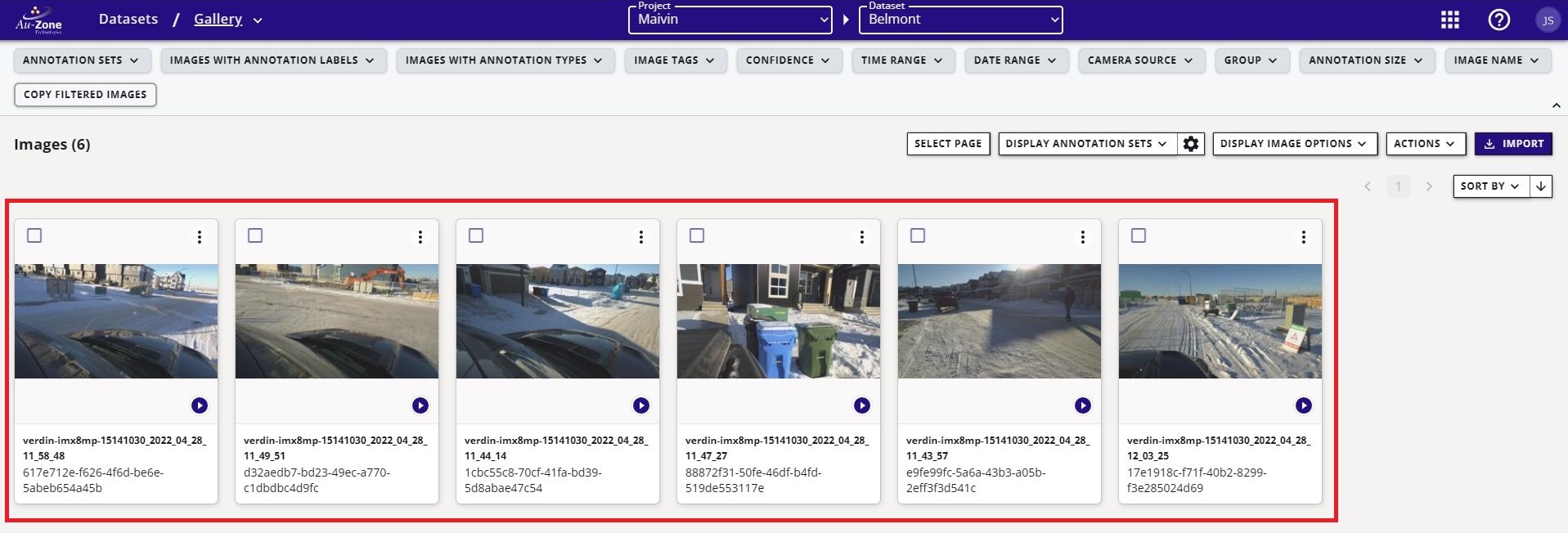
Clicking on any of these sequences will open individual images in the sequence with the visualizations of the annotations. For more information please see viewing datasets.
Datasets that train Fusion models provide annotations of the object's 3D bounding box. For more information on the dataset annotations, please see the EdgeFirst Dataset Format.
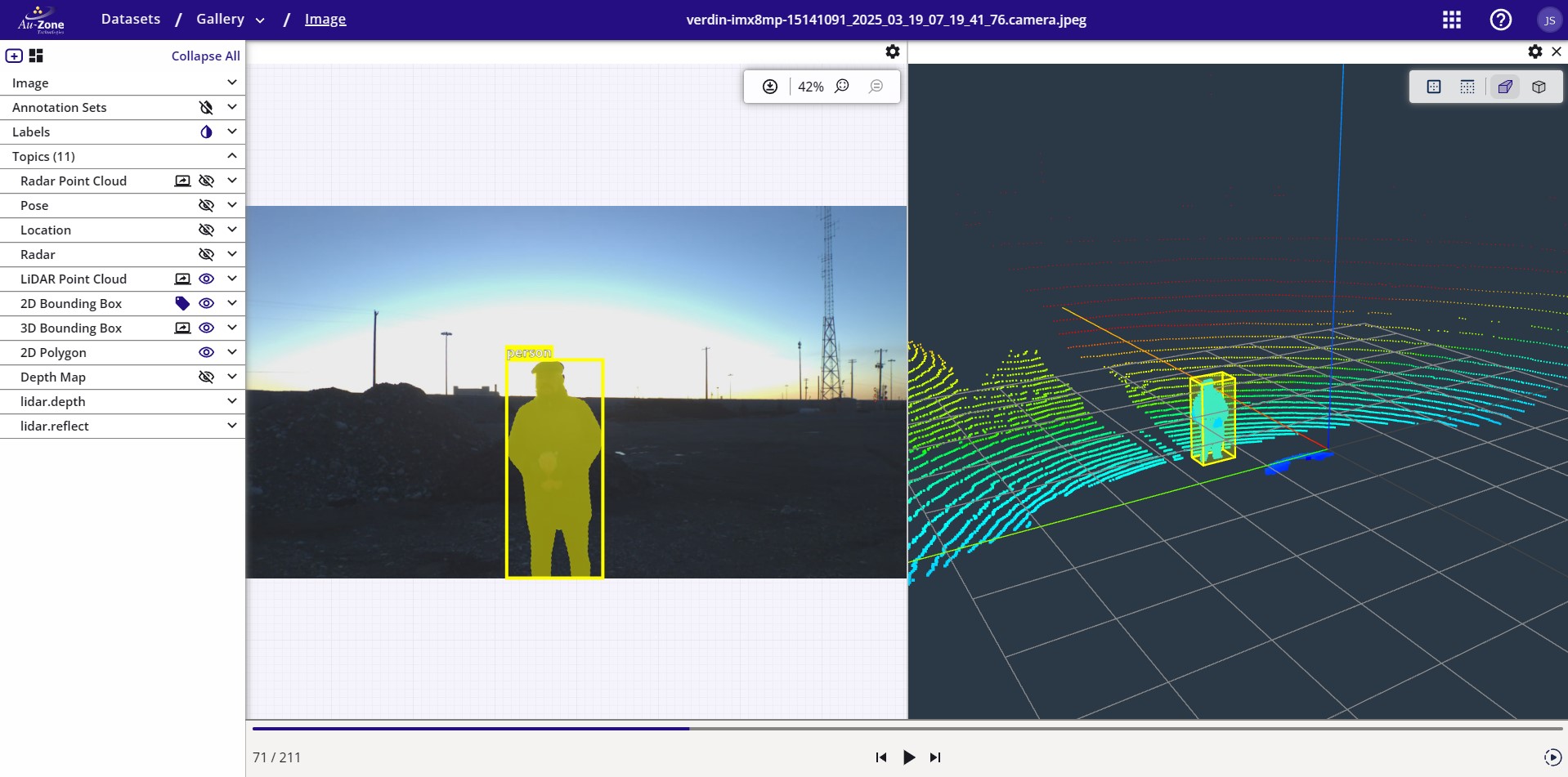
Datasets that train Vision models provide image annotations of the object's 2D bounding box and segmentation mask. For more information on the dataset annotations, please see the EdgeFirst Dataset Format.

For cases where the annotations need corrections, please see Manual 2D Annotations or Manual 3D Annotations for more details.
Create Dataset
If you have a video recording or sample images for your dataset, you can create a dataset container in EdgeFirst Studio to contain your video frames or images and annotations.
Navigate to a web browser and login to EdgeFirst Studio. Once logged in to EdgeFirst Studio, navigate to your project. In this case the project name is "Object Detection". Click on the "Datasets" button that is indicated in red below.
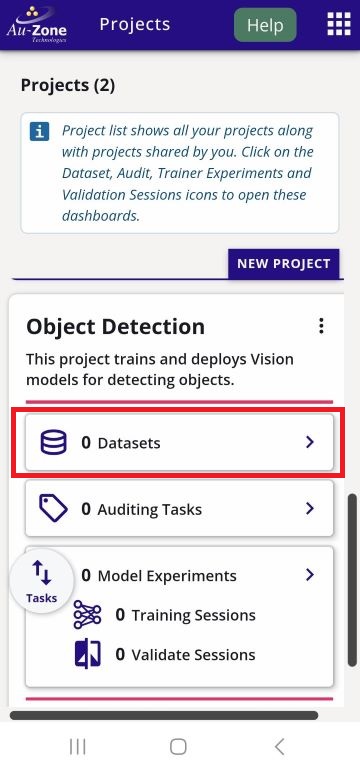
This will bring you to the "Datasets" page of the selected project. Create a new dataset container by clicking the "New Dataset" button that is indicated in red.
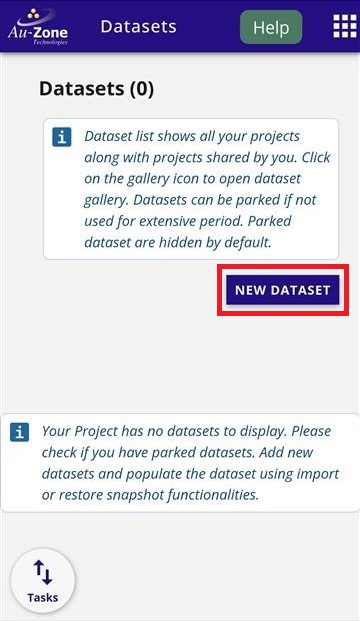
Add the dataset and annotation container name, labels, and dataset description as indicated by the fields below. It is up to you to specify the information in the fields and you do not have to strictly follow the example shown below. Click the "Create" button once the fields have been filled.
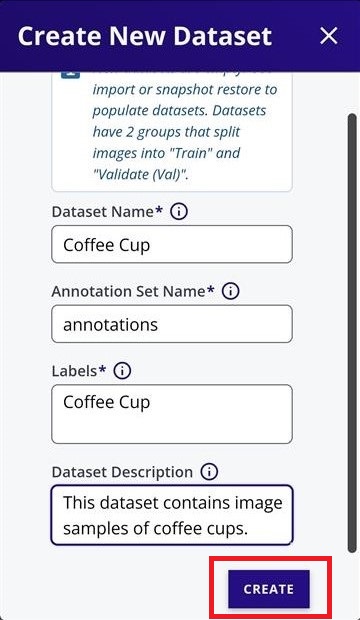
Your created dataset will look as follows.
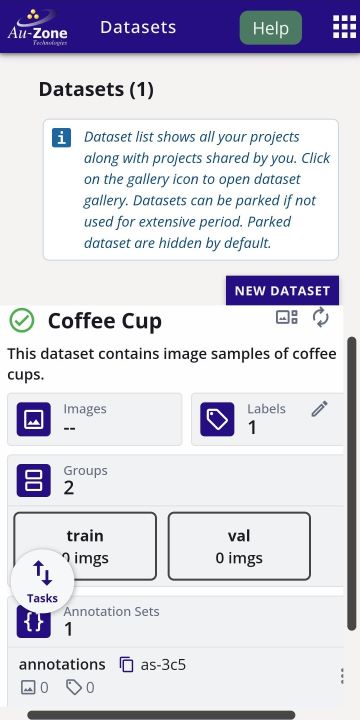
Copy Dataset
To copy a dataset, navigate to the dataset you would like to copy. On the dataset card, select "Copy Dataset" from the dataset options as shown below.
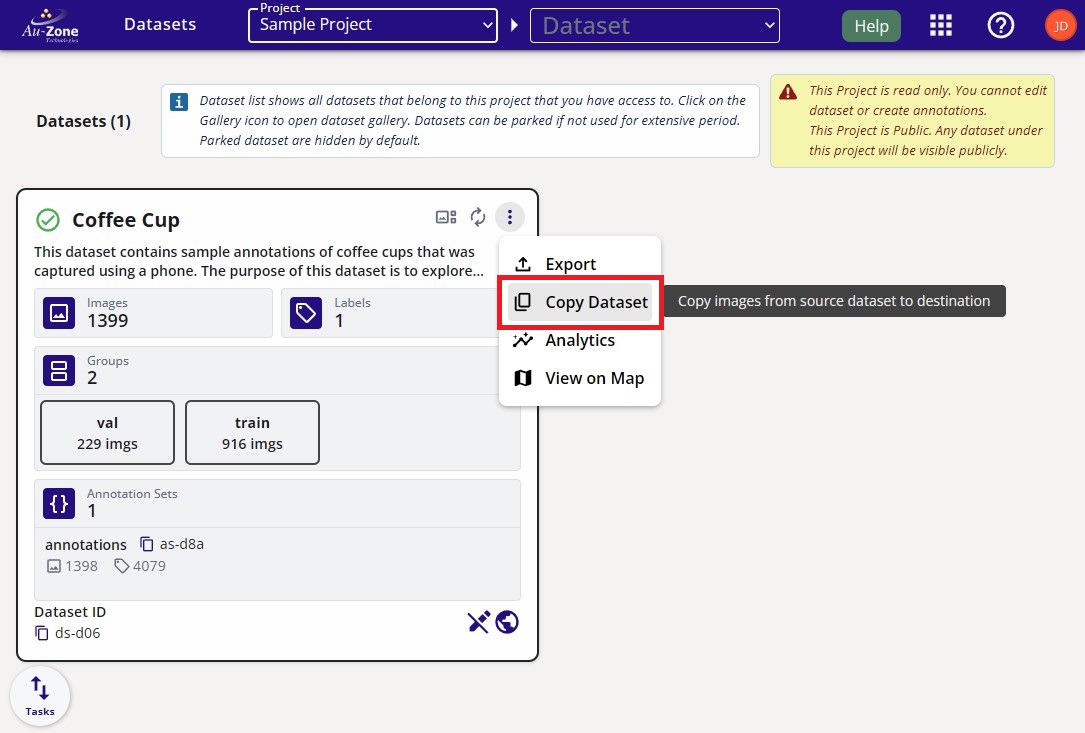
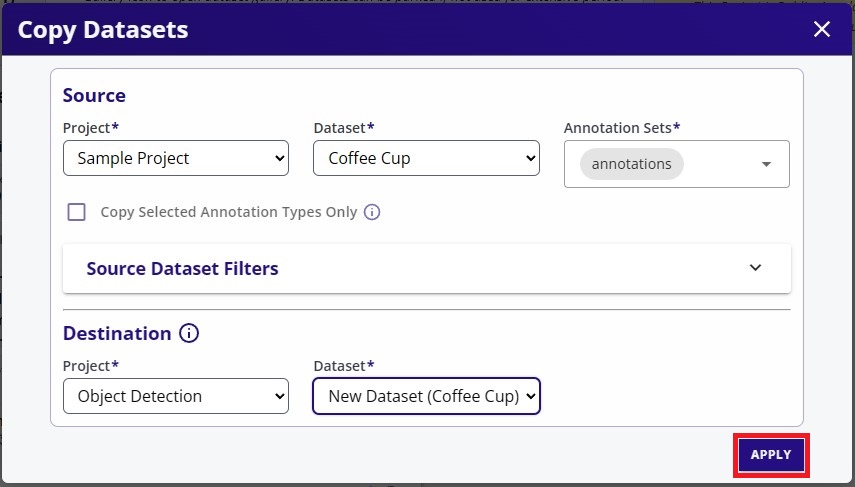
This will open a new dialog for the user to specify the dataset source and destination. The destination will be the location of the copied dataset. The source is the current location of the dataset. The source is set by default to the current dataset card you've selected. In the example below, the source is set to the "Coffee Cup" dataset from "Sample Project". The copied dataset will be placed as specified in the destination fields. By default a new dataset container will be created in the specified project. However, you can also create a dataset container before copying and specify this dataset container in the destination fields.
Once you have made your selection, click "Apply" at the bottom right to start the copy process.
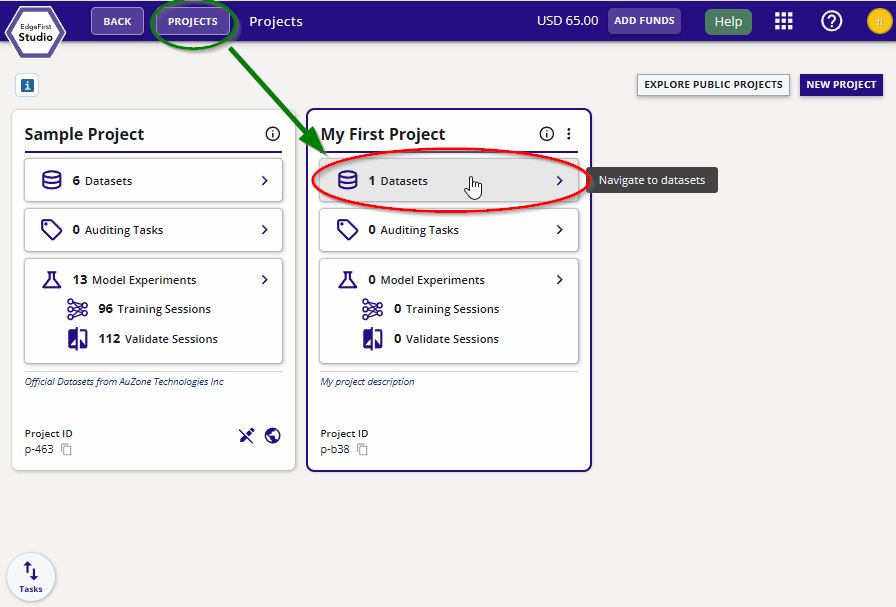
You can navigate to the copied dataset by clicking the "Project" button and then clicking on the "Datasets" button on your project as shown below.
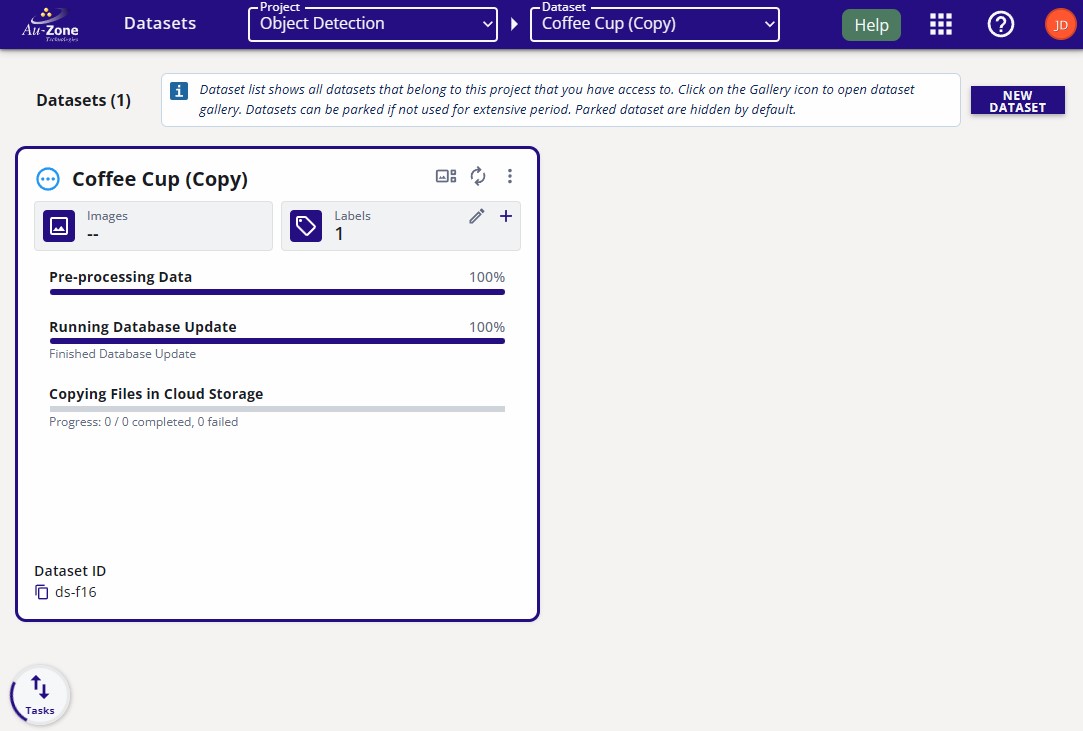
The progress for the dataset copy will be shown on the dataset card.
Once the copying process completes, the frames and the annotations would have been copied.
| Original Dataset | Copied Dataset |
|---|---|
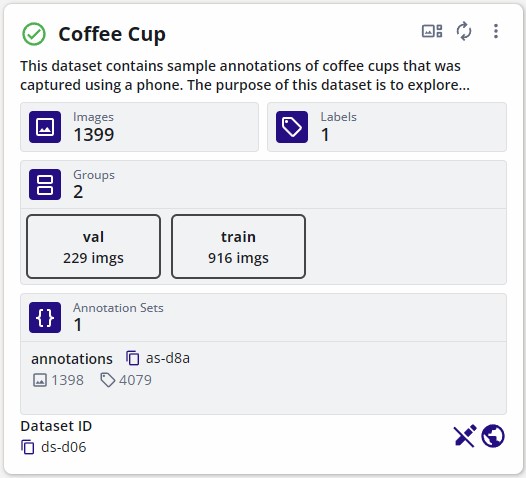 |
 |
Tag Dataset
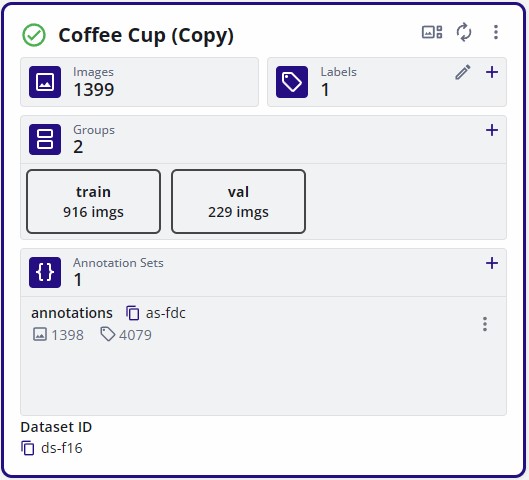
Before a dataset can be used for training, it must be tagged. To preserve its current state, assign a version tag to the dataset.
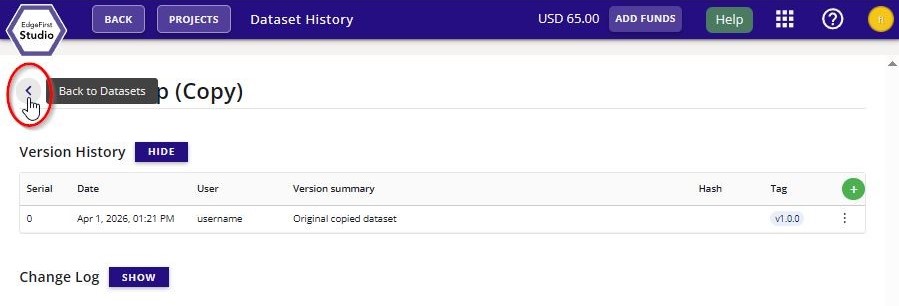
Click on the dataset options at the top right of the dataset card (three vertical dots). Then click the "History" button.
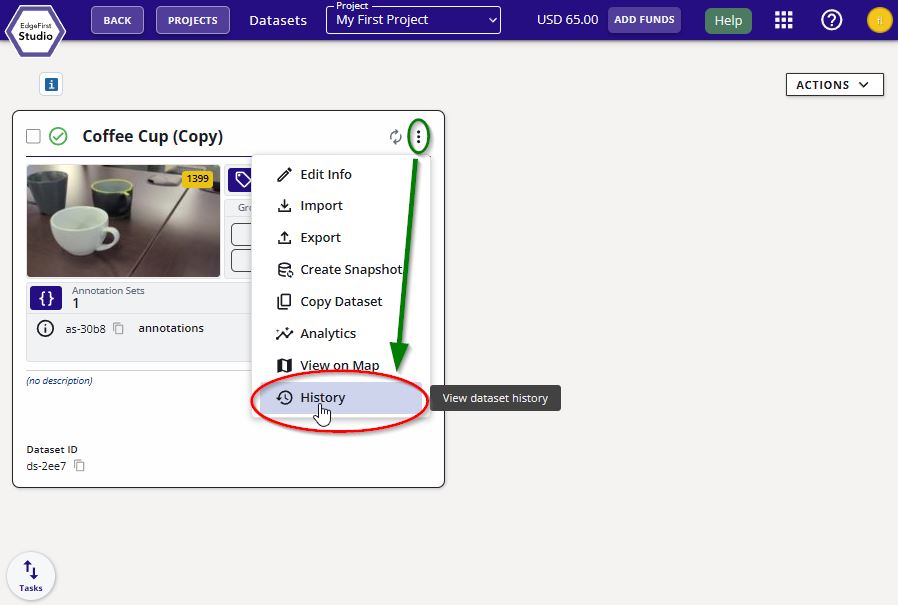
Add a new tagged version of the dataset by clicking the + green button on the right of the page as shown.
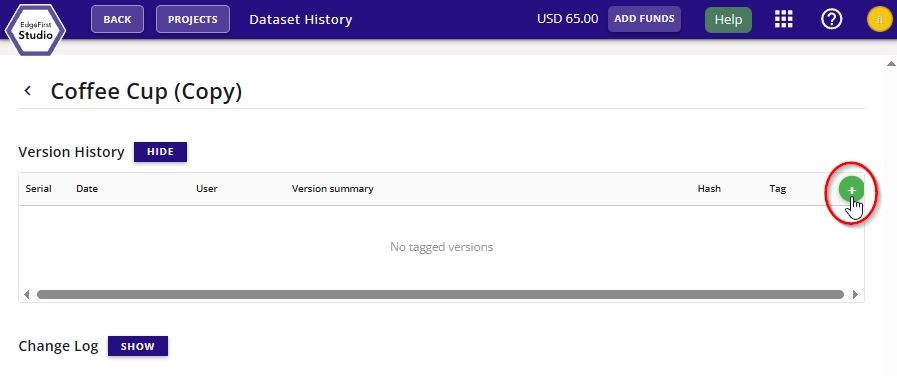
Specify the tag version and tag description. Click "Create Tag" to tag the dataset.
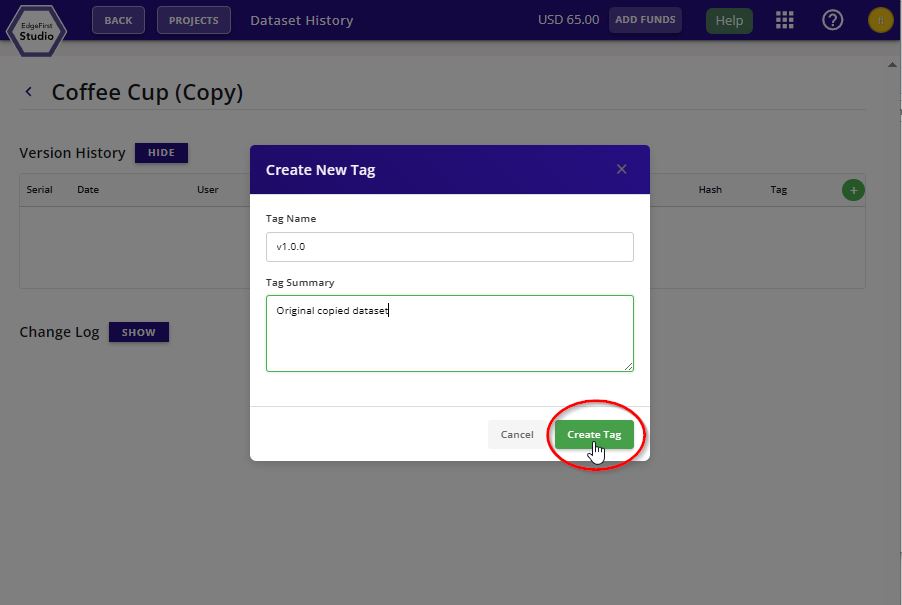
The new dataset tag will appear under "Version History" of this page. You can go back to the dataset card by clicking the "Back to Datasets" button.
Combine Datasets
The process of combining datasets consists of multiple copy processes on a given dataset container. To combine datasets, first create a dataset container. Follow the process for copying a dataset onto the destination dataset container that was created. The copy process will copy the selected dataset onto the same dataset container and thus combining multiple datasets.
Split Dataset
Partitioning the dataset is crucial in reserving dataset portions used for training and portions used for validation to assess the performance of the model. In EdgeFirst Studio, the partitions are 80% towards training and 20% towards validation. This operation randomly shuffles the data prior to assigning them to the specified groups.
Warning
The dataset needs to be re-split whenever new sample images or frames are added to the dataset. Newly added samples are not automatically added to any group that already exists.
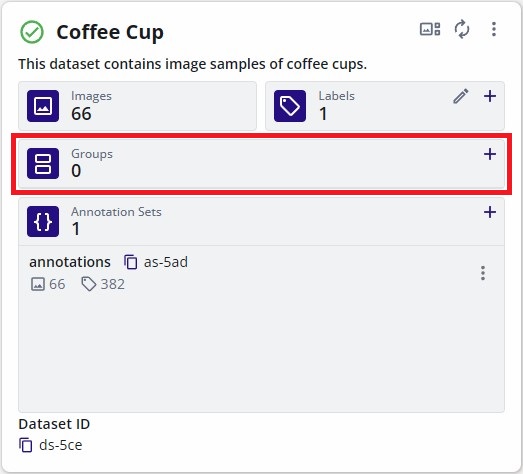
Consider the following dataset without any groups reserved.
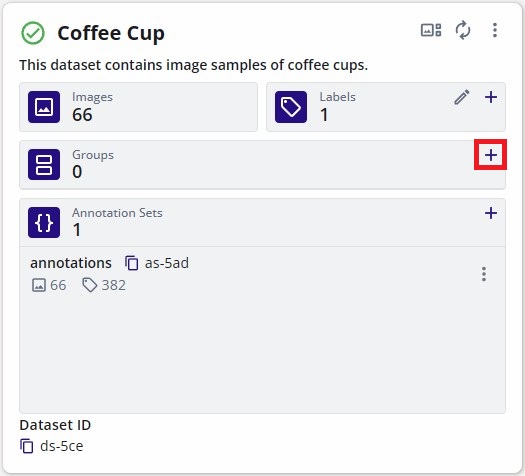
To create the dataset groups, click on the "+" button in the "Groups" field.
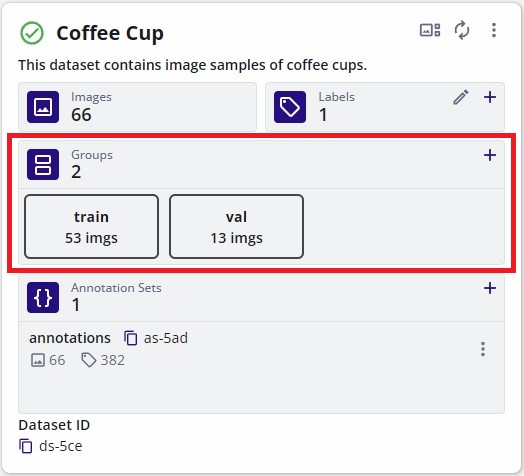
This will open a new dialog to specify the percentages of the partition belonging to the "Training" group or "Validation" group. By default 80% of the samples will be dedicated to training and 20% remaining will be dedicated towards the validation samples.

Once the groups are specified, click "Split" to create the groups. This will automatically divide the samples in the dataset based on the percentages of each group specified.
Export Dataset
Coming Soon